가격 목적에 따라 먼저 볼 사이트가 달라진다
출처: 다나와·PCPartPicker·TrendForce·Keepa 공개 기능 기준 자체 정리
출처: 다나와·PCPartPicker·TrendForce·Keepa 공개 기능 기준 자체 정리
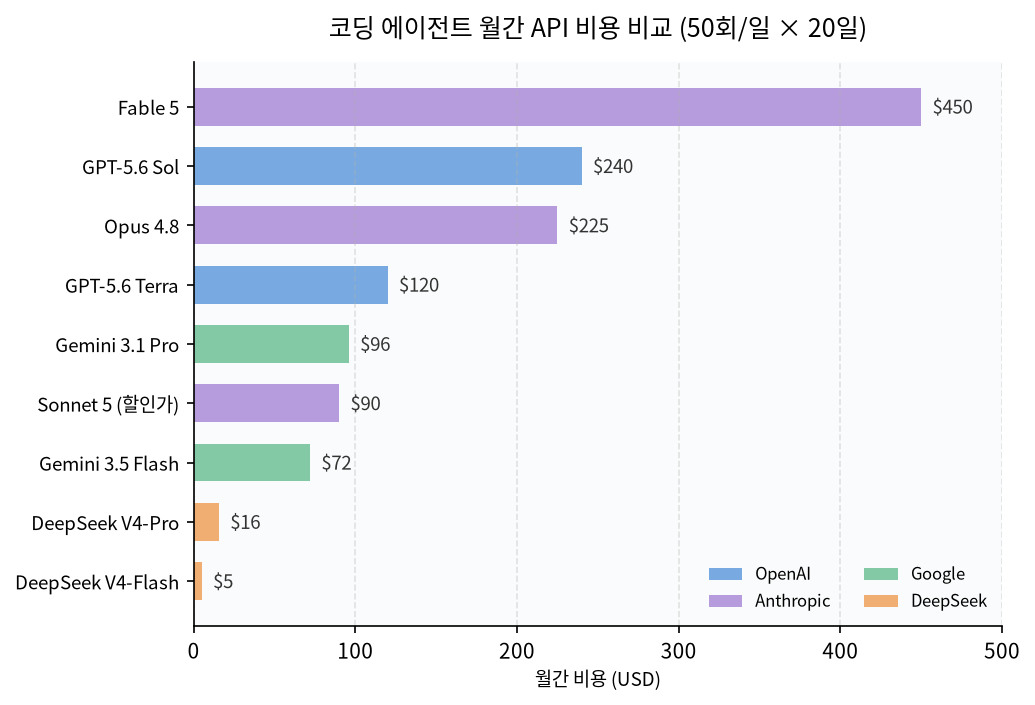
램 가격 변동 그래프 보는 곳 4곳: DDR4·DDR5·DRAM 가격 추이 읽는 법
램 가격 변동 그래프 보는 곳 4곳을 비교했다. 다나와, PCPartPicker, TrendForce, Keepa에서 DDR4·DDR5 소매가와 DRAM 현물가·계약가를 확인하는 방법을 정리했다.