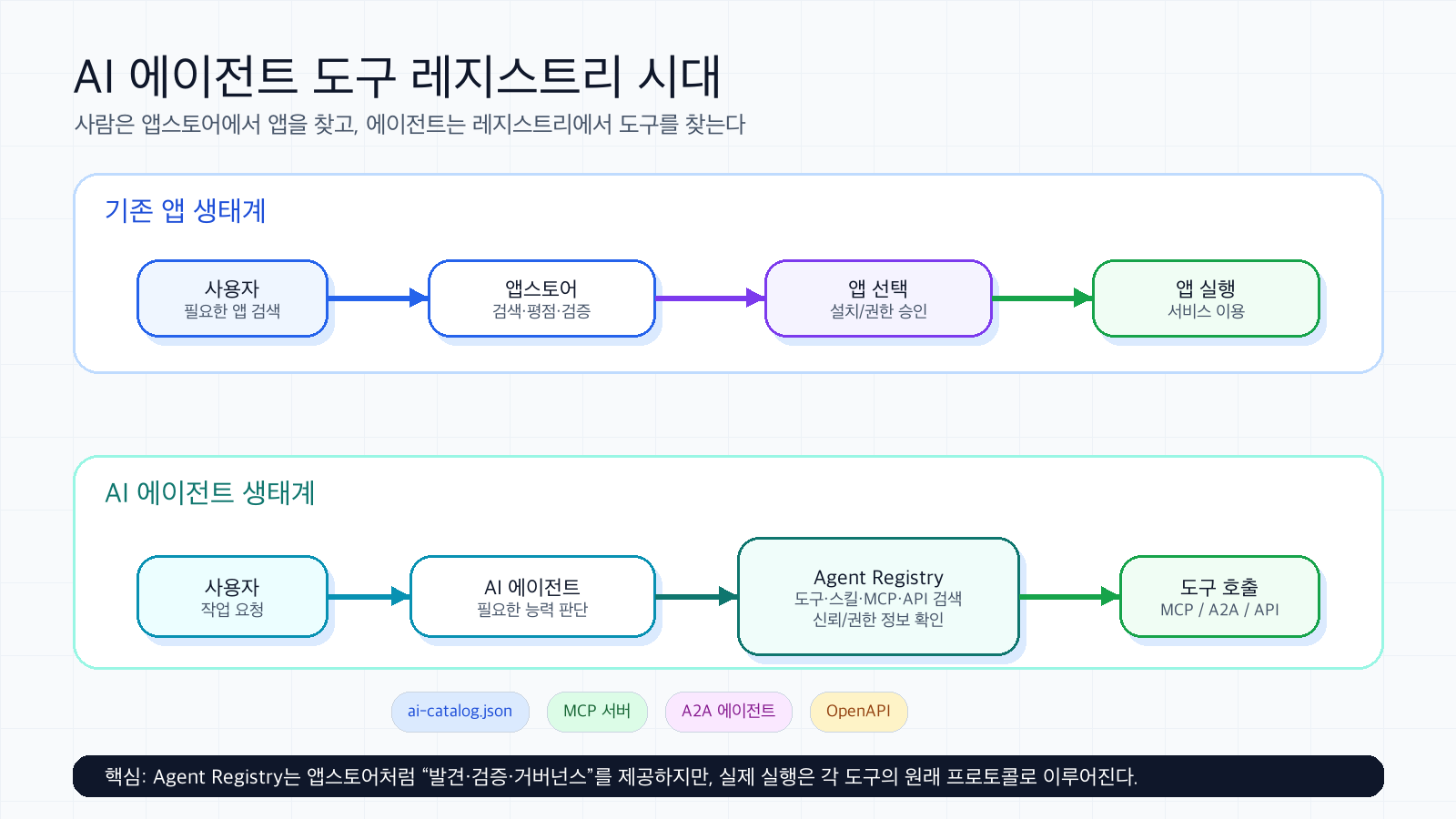
AI 모델 장애 분석에서 정말 중요한 능력은 로그를 많이 읽는 것이 아니라, 로그에 없는 레이어까지 가설을 확장하는 능력이다. 최근 WebSocket 기반 장기 연결 장애를 분석하면서 이 차이를 선명하게 느꼈다. 같은 단서가 주어졌는데도 어떤 모델은 ECS 롤링 교체와 heartbeat 단절에서 멈췄고, 어떤 모델은 NLB cross-zone, AZ별 target 공백, 외부 디바이스의 DNS 캐시 가능성까지 인과 사슬을 이어갔다.
- 문제는 WebSocket 연결이 끊긴 것보다 일부 단말이 12.5시간 동안 다시 붙지 못한 점이었다.
- AWS ECS Fargate 롤링 교체 뒤 특정 AZ의 NLB target이 비는 상황이 생겼다.
- NLB cross-zone이 꺼져 있으면 해당 AZ 노드로 들어온 TCP 연결은 정상 target으로 넘어가지 못할 수 있다.
- 일부 외부 디바이스가 DNS를 재조회하지 않고 캐시된 NLB IP로만 재시도했을 가능성이 가장 설득력 있었다.
- 모델 차이는 정답 문장보다 “어느 레이어까지 의심하고 검증했는가”에서 드러났다.
문제 상황: 일부 WebSocket 단말만 반나절 가까이 복구되지 않았다
사례는 실제 운영 장애를 바탕으로 하되 서비스명, 디바이스 종류, 정확한 수량, 테이블명은 익명화했다. 구조만 남기면 다음과 같다. AWS ECS Fargate에서 WebSocket 기반 장기 연결 서비스를 운영하고 있었고, 외부 IoT 디바이스들이 이 서비스에 지속 연결되어 heartbeat와 상태 이벤트를 보냈다.
야간에 Fargate 플랫폼 롤링 교체가 일어났다. 이 과정에서 태스크 하나가 교체됐고, 대부분의 디바이스는 정상적으로 재연결됐다. 그런데 특정 배치로 보이는 일부 디바이스는 마지막 heartbeat 이후 12.5시간 동안 재연결 로그가 남지 않았다. 오전에 서비스 전체를 재배포하자 몇 분 안에 해당 디바이스들이 일제히 복구됐다.
| 관찰된 현상 | 처음 떠오르는 해석 | 실제로 더 봐야 할 질문 |
|---|---|---|
| 야간 ECS 태스크 롤링 교체 | 배포 중 연결이 끊겼다 | 왜 대부분은 돌아왔는데 일부만 못 돌아왔나 |
| heartbeat 미수신 뒤 unavailable 전환 | health scheduler가 상태를 바꿨다 | 상태 전환은 원인인가, 증상인가 |
| HMI 또는 앱 재시작으로 복구 안 됨 | 클라이언트 앱 문제일 수 있다 | 네트워크 목적지가 계속 같은 곳이었나 |
| 서비스 재배포 후 일괄 복구 | 애플리케이션 재시작으로 고쳐졌다 | 재배포가 정확히 어떤 리소스를 회복시켰나 |
처음에는 애플리케이션 문제처럼 보였다
처음 의심한 지점은 애플리케이션이었다. WebSocket 서버가 연결된 디바이스를 in-memory map에 보관하고 있었다면, 죽은 세션이 남아 신규 연결을 거부했을 가능성이 있다. 또는 health scheduler가 heartbeat 미수신을 보고 unavailable 상태로 바꾸면서 복구 흐름을 꼬이게 만들었을 수도 있다.
코드와 로그를 보면 이 가설은 일부만 맞았다. heartbeat 미수신 뒤 서버가 unavailable 상태로 바꾼 것은 맞다. 그러나 그것은 원인이라기보다 증상이었다. 중복 연결을 명시적으로 거부하는 로직도 확인되지 않았다. 더 중요한 사실은 장애 시간 동안 문제 디바이스들의 재연결 시도가 서버 애플리케이션 로그에 거의 나타나지 않았다는 점이었다.
많은 분석은 “끊긴 이유”에서 멈춘다
이 장애에서 중요한 질문은 “왜 끊겼는가”가 아니라 “왜 다시 붙지 못했는가”였다. ECS 롤링 교체로 WebSocket이 끊기는 일은 충분히 있을 수 있다. 실제로 대부분의 디바이스는 교체 직후 다시 연결됐다. 이상한 지점은 특정 디바이스만 12.5시간 동안 복귀하지 못했다는 사실이다.
여러 모델의 분석을 비교해보면 이 차이가 분명했다. 어떤 모델은 ECS 교체, 마지막 heartbeat, health scheduler, 수동 재배포 후 복구까지 사실관계를 정확히 정리했다. 하지만 “왜 일부만 돌아오지 못했는가”라는 질문에는 도달하지 못했다. 사실관계는 맞지만 인과 사슬의 마지막 고리가 빠진 셈이다.
더 깊은 가설: NLB cross-zone OFF와 AZ target 공백
더 설득력 있는 가설은 네트워크 경로에서 나왔다. 서비스는 NLB 뒤에 있었고, NLB cross-zone load balancing은 꺼져 있었다. ECS Fargate 태스크는 ap-northeast-2a와 ap-northeast-2b에 배치될 수 있었지만, 롤링 교체 이후 결과적으로 한쪽 AZ의 소켓 target이 비는 상태가 만들어졌다.
NLB는 L4 로드밸런서다. HTTP 200이나 4xx를 만들어주는 계층이 아니다. cross-zone이 꺼져 있고 특정 AZ에 healthy target이 없으면, 그 AZ의 NLB 노드로 들어온 TCP 연결은 정상 WebSocket 핸드셰이크까지 가지 못한다. 이 경우 서버 애플리케이션은 연결 시도 자체를 보지 못한다.
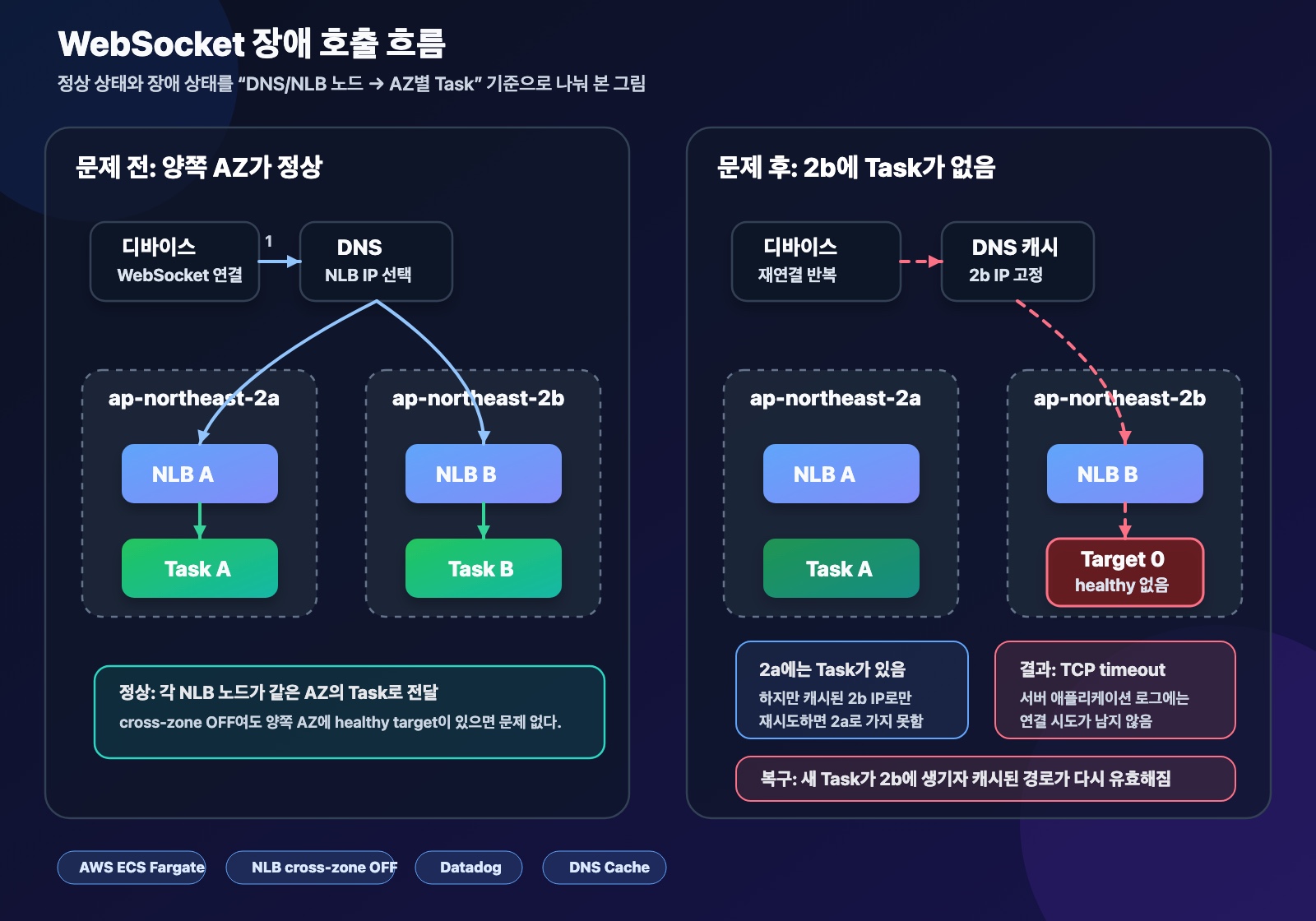
문제 전후 호출 흐름을 그림으로 보면
이 장애를 이해하려면 디바이스가 “서비스”로 붙는다고 뭉뚱그리지 말고, DNS가 돌려준 NLB 노드 IP와 그 노드가 바라보는 AZ별 target을 분리해서 봐야 한다. 아래 흐름도처럼 문제 전에는 양쪽 AZ에 healthy target이 있었고, 문제 후에는 ap-northeast-2b 쪽 target이 0개인 상태에서 일부 디바이스가 캐시된 2b IP로만 재시도한 것으로 해석할 수 있다.
| 증거 | 의미 | 해석 |
|---|---|---|
| AZ별 healthy target 공백 | 특정 AZ에 전달 가능한 태스크가 없음 | NLB cross-zone OFF에서 치명적 |
| Datadog NLB NewFlowCount 증가 | 클라이언트가 계속 연결을 시도함 | 디바이스가 멈춘 것이 아님 |
| 서버 인증·연결 로그 부재 | 요청이 애플리케이션까지 도달하지 않음 | 서버 거부보다 네트워크 경로 문제에 가까움 |
| Reset 카운트 급증 없음 | 명시적 거절보다 timeout 패턴 | TCP silent drop 또는 무응답에 가까운 경험 |
| 신규 target 등록 직후 일괄 복구 | 비어 있던 경로가 회복됨 | 재배포 자체보다 AZ target 회복이 핵심 |
마지막 퍼즐: 왜 같은 NLB IP로만 계속 갔을까
여기서 한 가지 의문이 남는다. AWS는 특정 AZ에 healthy target이 없으면 DNS 응답에서 해당 AZ 노드를 제외할 수 있다. 그렇다면 왜 문제 디바이스들은 정상 AZ로 넘어가지 못했을까. 가장 그럴듯한 답은 외부 디바이스의 DNS 캐시 또는 IP 고정 재시도 동작이었다.
임베디드 디바이스나 현장 단말은 부팅 시 한 번 DNS를 조회한 뒤 TTL을 엄격히 따르지 않고 같은 IP로 계속 재시도하는 경우가 있다. 이 경우 DNS failover는 재조회하는 클라이언트에게만 효과가 있다. 캐시된 ap-northeast-2b 쪽 NLB IP로만 재시도하는 디바이스는 2b에 target이 다시 생길 때까지 계속 timeout을 겪을 수 있다.
이 가설은 복구 패턴과도 맞았다. 일부 디바이스는 서비스 재배포 전 완전 재부팅 뒤 먼저 복구된 것으로 보였다. 반면 나머지는 비어 있던 AZ에 새 target이 등록된 직후 일제히 복구됐다. 디바이스 쪽 설정이 갑자기 바뀐 것이 아니라, 캐시된 목적지의 반대편에 다시 target이 생긴 것이다.
재배포로 복구됐다는 사실을 조심해서 읽어야 한다
재배포 후 복구됐다는 사실은 종종 애플리케이션 문제처럼 보인다. 하지만 이 사례에서는 재배포 자체가 해결책이 아니라, 비어 있던 AZ에 새 target이 생긴 것이 복구 메커니즘이었다. 만약 재배포 후 새 태스크가 다시 같은 AZ에만 쏠렸다면 동일한 문제가 이어졌을 가능성도 있다.
그래서 runbook에 “이런 경우 재배포”라고만 남기면 위험하다. 더 정확한 runbook은 “NLB target group의 AZ별 healthy target을 확인하고, cross-zone 설정과 ECS task 배치를 확인하라”가 되어야 한다. 재배포는 결과적으로 target 분포를 회복시킨 조치였지, 원인 그 자체를 제거한 조치는 아니었다.
AI 모델별 차이는 어디에서 드러났나
이 사례에서 인상적이었던 점은 모델별 차이가 단순한 문장력이나 요약력에서 나오지 않았다는 것이다. 여러 모델이 ECS 교체, heartbeat 미수신, health scheduler, 수동 재배포 후 복구라는 사실관계를 잡아냈다. 그 자체도 유용했다. 그러나 더 날카로운 분석은 거기서 한 질문을 더 던졌다.
“왜 대부분은 다시 붙었는데, 일부만 12.5시간 동안 다시 붙지 못했나?”
이 질문 하나가 분석 범위를 애플리케이션 코드에서 NLB, AZ, Datadog 메트릭, DNS, 외부 디바이스 펌웨어 동작까지 넓혔다. 좋은 AI 트러블슈터는 로그를 요약하는 모델이 아니라, 빠진 질문을 만들어내고 그 질문을 검증할 지표를 찾는 모델이라는 생각이 들었다.
| 평가 축 | 얕은 분석 | 깊은 분석 |
|---|---|---|
| 애플리케이션 로그 | 마지막 heartbeat와 unavailable 전환을 정리 | 서버 로그 부재를 네트워크 미도달 증거로 해석 |
| 코드 분석 | health scheduler와 session map 확인 | 재연결 거부 로직 부재로 가설을 기각 |
| 인프라 분석 | ECS 롤링 교체를 트리거로 지목 | AZ별 target 공백과 NLB cross-zone 설정까지 확인 |
| 네트워크 분석 | WebSocket 재연결 실패로 표현 | TCP timeout, reset 부재, DNS 캐시 가능성으로 분해 |
| 복구 해석 | 재배포로 복구 | 비어 있던 AZ에 target이 생겨 복구 |
운영 장애 분석에서 AI를 쓸 때의 체크리스트
- “왜 끊겼나”와 “왜 다시 붙지 못했나”를 분리한다.
- 재배포 후 복구됐다고 해서 애플리케이션 문제로 단정하지 않는다.
- 서버 로그가 없다는 사실도 중요한 증거로 본다.
- NLB target group의 AZ별 healthy target을 확인한다.
- NLB cross-zone 설정과 ECS Fargate task placement를 함께 본다.
- Datadog에서 NewFlowCount, reset count, target health를 같은 시간축으로 맞춘다.
- 외부 디바이스가 DNS TTL을 준수하는지, 실패 시 재조회하는지 확인한다.
- AI 모델의 결론보다 모델이 다음에 보라고 제안하는 지표를 평가한다.
재발 방지 관점의 기술 메모
이 유형의 장애를 줄이려면 NLB cross-zone load balancing 활성화가 가장 직접적이다. 특정 AZ의 target이 비어도 다른 AZ의 healthy target으로 전달할 수 있기 때문이다. ECS availability zone rebalancing도 검토할 만하다. 다만 WebSocket 장기 연결 서비스에서는 재배치 자체가 대량 재연결을 만들 수 있으므로, 운영 시간과 drain 전략을 함께 설계해야 한다.
모니터링은 애플리케이션 상태만 보면 늦다. AZ별 HealthyHostCount, WebSocket disconnect 급증, heartbeat 미수신 단말 수, unavailable 전환 급증, NLB NewFlowCount와 reset count를 함께 보아야 한다. 특히 “연결 시도는 늘었는데 서버 로그가 없다”는 조합은 네트워크 경로 문제를 강하게 의심하게 만드는 신호다.
결론: 좋은 모델은 로그 밖의 세계를 본다
이번 사례에서 놀라웠던 지점은 특정 모델이 장애 원인을 단번에 맞혔다는 것이 아니다. 더 정확히는, 그 모델이 애플리케이션 로그 바깥으로 사고를 확장했다는 점이다. ECS Fargate, ap-northeast-2a/2b 배치, NLB cross-zone, Datadog 메트릭, DNS 캐시, 외부 디바이스 동작을 하나의 인과 사슬로 연결했다.
AI 모델 평가는 코딩 속도나 벤치마크 점수만으로 충분하지 않다. 실제 운영에서는 “맞는 말을 했는가”보다 “어디까지 의심했는가”, “무엇으로 반증했는가”, “다음 장애 때 runbook을 더 낫게 만들었는가”가 더 중요할 때가 있다. 이 사례는 AI 트러블슈팅 능력을 평가할 때 추론 반경이라는 별도의 축이 필요하다는 것을 보여준다.
FAQ
AI 모델로 운영 장애를 분석할 때 가장 중요한 평가 기준은 무엇인가?
단순 정답보다 추론 반경과 반증 능력이 중요하다. 좋은 모델은 애플리케이션 로그 요약에서 멈추지 않고 인프라, 네트워크, 클라이언트 동작까지 가설을 확장한 뒤 메트릭으로 검증한다.
WebSocket 장애에서 재배포 후 복구됐으면 애플리케이션 문제가 맞나?
반드시 그렇지는 않다. 재배포로 새 target이 비어 있던 AZ에 등록되면서 네트워크 경로가 회복될 수 있다. 따라서 재배포 후 복구라는 사실만으로 애플리케이션 버그라고 단정하면 안 된다.
NLB cross-zone 비활성화가 왜 장기 연결 장애로 이어질 수 있나?
cross-zone이 꺼진 NLB는 각 AZ 노드가 같은 AZ의 healthy target으로 트래픽을 전달한다. 특정 AZ에 target이 0개가 되면 그 AZ 노드로 접속하는 클라이언트는 연결 타임아웃을 겪을 수 있다.
DNS 캐시 가설은 어떻게 검증할 수 있나?
서버 로그 부재, NLB NewFlowCount 증가, reset 카운트 부재, 일부 단말의 전원 재부팅 후 선복구, 비어 있던 AZ에 새 target이 생긴 직후 일괄 복구 같은 신호가 함께 맞아야 한다. 가능하다면 VPC Flow Logs와 단말 펌웨어의 DNS 재조회 동작도 확인한다.
함께 읽을 글
참고 자료
- AWS: Network Load Balancers
- AWS: Amazon ECS on AWS Fargate
- AWS: Target groups for Network Load Balancers
- Datadog: AWS ELB integration