AI 코딩 에이전트를 고를 때는 모델 벤치마크 순위보다 “내 코드베이스에서 끝까지 일하게 만들 수 있는가”를 봐야 한다. Claude Code, Codex, Antigravity CLI, GLM-5.2는 모두 코드 작성 능력을 강조하지만 실제 선택 기준은 다르다. 중요한 것은 답변이 그럴듯한지가 아니라, 파일을 읽고 고치고 테스트하고 실패를 복구한 뒤 사람이 리뷰 가능한 결과를 남기는가다.

빠른 결론
- 안정적인 장기 코딩 작업은 Claude Code 계열이 강한 편이다.
- OpenAI 생태계와 코드 리뷰·에이전트 통합을 중시한다면 Codex가 자연스럽다.
- 터미널 중심, 오픈소스 CLI, 무료 사용량, Google Search grounding을 중시한다면 Antigravity CLI가 현재 기준에 더 맞다.
- 오픈 모델, 자체 호스팅 가능성, 긴 컨텍스트·코딩 벤치마크를 보고 싶다면 GLM-5.2 계열을 검토할 만하다.
- 하지만 어느 하나가 항상 정답은 아니다. 과제 유형, 도구 권한, 테스트 환경, 비용 구조에 따라 결과가 바뀐다.
실제 가격부터 확인하자: 플랜별 차이
AI 코딩 에이전트 선택 기준에서 가격은 부가 정보가 아니라 핵심 정보다. 같은 “월 구독”이라도 포함되는 사용량, 코딩 도구 지원 범위, MCP 제공량, API 토큰 과금 여부가 다르다. 그래서 단순히 “월 100달러부터”처럼 적으면 부족하다. 아래 표는 공식 가격·구독 페이지를 직접 확인해 정리한 플랜별 차이다.
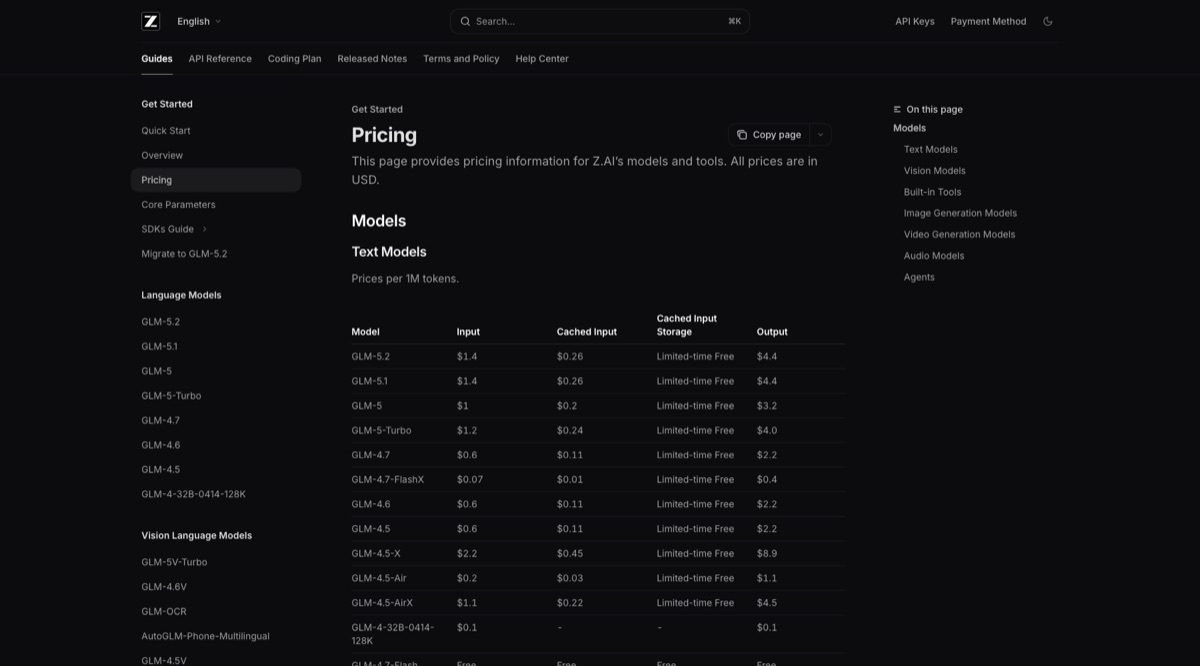
용어 정리: GLM-5.2 자체는 코딩 에이전트가 아니라 모델이다. 따라서 이 글에서 비교 대상으로 다루는 것은 GLM-5.2 모델 자체가 아니라, GLM-5.2·GLM-5-Turbo·GLM-4.7을 Claude Code, Cline, OpenCode 같은 코딩 도구에서 쓰게 해주는 Z.ai GLM Coding Plan이다. API 토큰 가격은 별도 항목으로 분리해 본다.
| 대상 | 플랜/가격 | 코딩 에이전트 관점의 차이 |
|---|---|---|
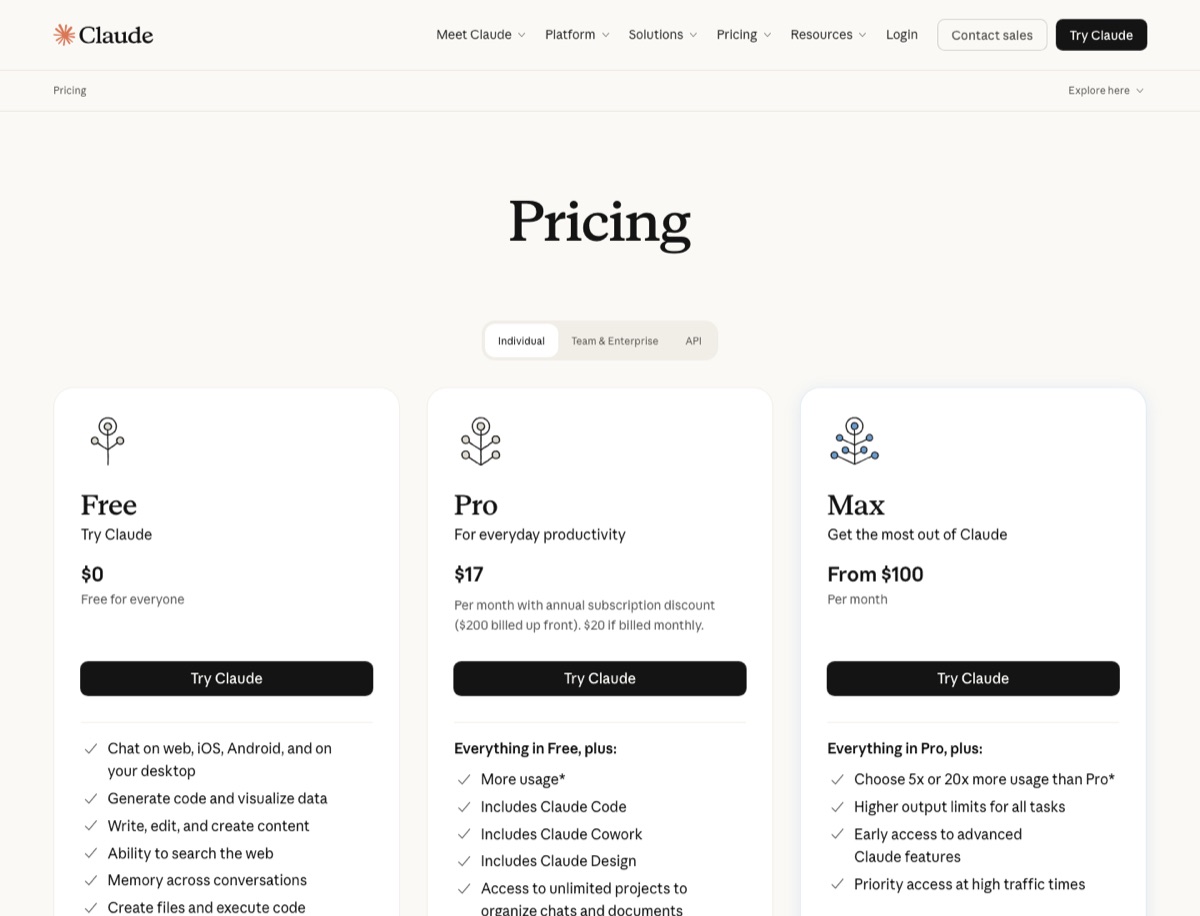
| Claude Code | Free $0, Pro $17/월(연간 $200 선결제) 또는 $20/월, Max 5x $100/월, Max 20x $200/월 | Pro부터 Claude Code가 포함된다. Max는 Pro보다 5x 또는 20x 더 많은 사용량을 선택하는 구조이며, 장시간 코딩 세션이 많으면 Pro보다 Max 계층을 봐야 한다. |
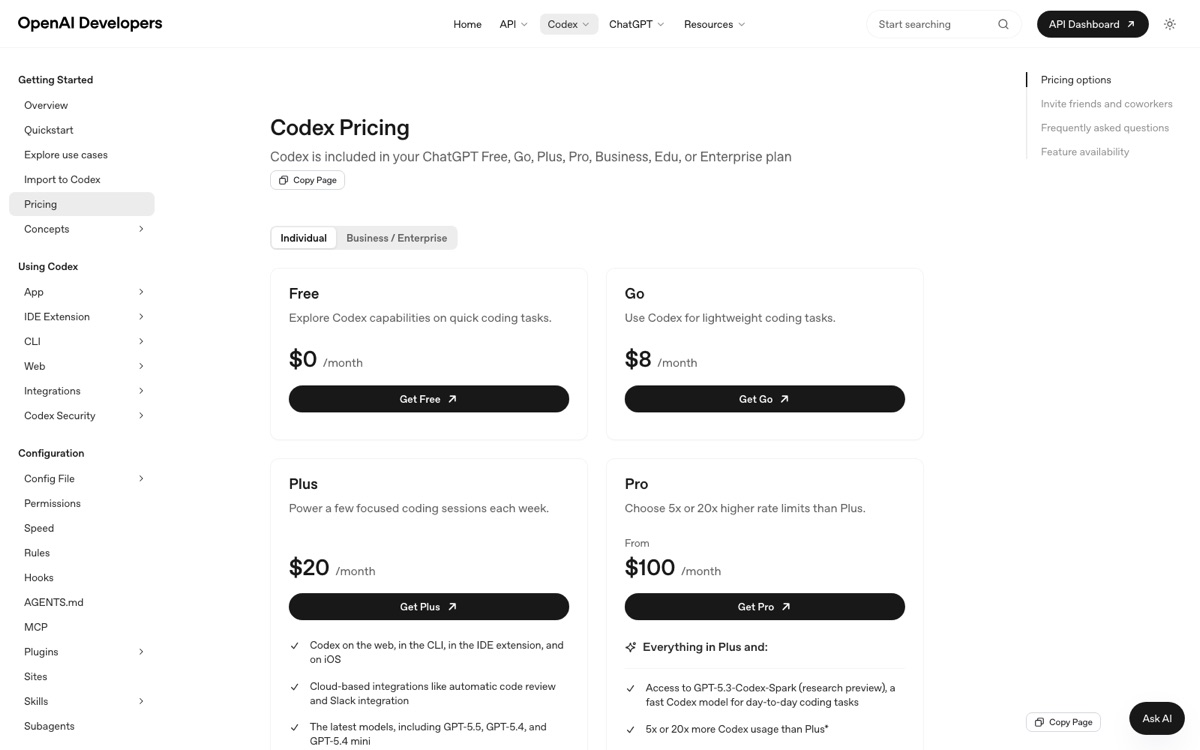
| OpenAI Codex | Free $0/월, Go $8/월, Plus $20/월, Pro는 $100/월이 5x 또는 $200/월이 20x 더 높은 사용량 옵션 | Codex는 Free, Go, Plus, Pro, Business, Edu, Enterprise에 포함된다. Plus부터 web/CLI/IDE/iOS와 클라우드 코드 리뷰·Slack 통합 같은 기능이 본격적으로 들어가고, Pro는 Plus보다 높은 사용량을 제공한다. |
| Antigravity CLI | Google 개인 무료 티어 사용자의 후속 CLI 흐름이다. 별도의 월 구독 가격표보다는 Google Code Assist/Antigravity 계정 조건과 전환 공지를 확인해야 한다. | 기존 무료 CLI 사용자는 Antigravity CLI 마이그레이션 여부를 먼저 확인해야 한다. 기업 사용자는 Gemini Code Assist Standard/Enterprise 플랜과 별도로 비교해야 한다. |
| GLM Coding Plan | Lite $18/월, Pro $72/월, Max $160/월. 연간 결제 기준 각각 $12.6/월, $50.4/월, $112/월로 표시된다. | Lite는 소형 repo와 가벼운 반복 작업, Pro는 Lite의 5배 사용량과 중형 repo 일상 개발, Max는 Lite의 20배 사용량과 중대형 repo·고빈도 작업을 겨냥한다. |
| GLM Coding Plan 사용량 | Lite 약 80 prompts/5h·400 prompts/week, Pro 약 400 prompts/5h·2,000 prompts/week, Max 약 1,600 prompts/5h·8,000 prompts/week | GLM-5.2와 GLM-5-Turbo는 고급 모델로 peak/off-peak에 따라 quota 차감 배율이 달라질 수 있다. 문서 기준 Web Search/Web Reader/Zread MCP 월 한도는 Lite 100, Pro 1,000, Max 4,000 calls다. |
| GLM-5.2 API | 1M tokens 기준 input $1.4, cached input $0.26, output $4.4 | Claude Code·Cline·OpenCode 같은 지원 도구에서 쓰는 Coding Plan과, 자체 도구/서버에 붙이는 API 토큰 과금은 별도로 봐야 한다. |
구독·가격 공식 페이지 링크
- Claude / Claude Code 가격 페이지 — Free, Pro, Max 5x, Max 20x 플랜을 확인할 수 있다.
- OpenAI Codex 가격 페이지 — Free, Go, Plus, Pro, Business/Enterprise 및 API Key 과금 안내를 확인할 수 있다.
- Google Code Assist / Antigravity 전환 안내 페이지 — 기존 Gemini CLI 개인 무료 티어가 Antigravity CLI로 전환되는 공지를 확인할 수 있다.
- Z.ai GLM Coding Plan 구독 페이지 — Lite, Pro, Max 월간·연간 구독 가격과 사용량 차이를 확인할 수 있다.
- Z.ai 모델/API 가격 페이지 — GLM-5.2 등 모델별 input, cached input, output 토큰 단가를 확인할 수 있다.
비교 대상 4가지
| 도구/모델 | 강점 | 주의할 점 | 잘 맞는 상황 |
|---|---|---|---|
| Claude Code | 긴 작업 흐름, 코드베이스 이해, 수정 계획과 리뷰 가능성이 좋다 | 비용과 속도, 세션/권한 설정을 관리해야 한다 | 복잡한 리팩터링, 테스트 기반 구현, 긴 문서 기반 작업 |
| Codex | OpenAI 개발자 생태계와 잘 맞고 “어디서든 쓰는 코딩 에이전트” 포지션이 강하다 | 프로젝트별 권한·자동화 범위를 명확히 제한해야 한다 | 코드 리뷰, GitHub 흐름, 자동 수정 루프 |
| Antigravity CLI | Google 개인 무료 티어 흐름을 이어받는 터미널/에이전트 선택지다 | Antigravity CLI 전환 구간이라 공식 마이그레이션 공지를 확인해야 한다 | Google 개인 무료 티어 사용자, 터미널 중심 개발자, 검색 기반 조사+수정 |
| GLM-5.2 계열 | 오픈 모델/자체 운영 가능성, 긴 컨텍스트, 코딩 벤치마크 기대감이 있다 | 클라이언트·API 안정성, 도구 호출 품질, 실제 에이전트 루프 검증이 필요하다 | 오픈소스 모델 검토, 사내 배포, 비용 통제, 벤치마크 대비 실험 |
선택 기준 1. 도구 호출 안정성
AI 코딩 에이전트는 채팅 모델이 아니다. 실제로는 파일 읽기, 검색, 패치, 테스트 실행, 브라우저 확인, Git 작업을 반복하는 도구 실행 시스템이다. 따라서 모델이 똑똑해 보여도 tool call이 불안정하면 실무 생산성은 떨어진다.
확인해야 할 것은 단순하다. 파일을 잘못 덮어쓰지 않는가, 실패한 명령을 보고 원인을 좁히는가, 권한이 필요한 작업에서 멈추고 설명하는가, 장시간 작업 중 세션이 끊기지 않는가다. 특히 GLM-5.2 같은 오픈 모델을 외부 CLI에 붙여 쓸 때는 모델 능력과 클라이언트 안정성을 분리해서 봐야 한다.
선택 기준 2. 컨텍스트 관리 능력
큰 코드베이스에서 중요한 것은 많은 토큰을 넣는 능력보다 “필요한 파일을 고르고, 바뀐 요구사항을 잊지 않고, 이전 실패를 반복하지 않는 능력”이다. 긴 컨텍스트 모델이라도 근거 파일을 제대로 압축하지 못하면 결과는 흔들린다.
문서 기반 과제에서는 이 차이가 더 선명하다. 정책 문서, acceptance test, 기존 코드 스타일, 배포 규칙을 동시에 읽어야 하기 때문이다. Claude Code는 이런 장기 작업에서 강한 인상을 주는 경우가 많고, GLM 계열은 긴 컨텍스트와 코딩 벤치마크를 내세우지만 실제 에이전트 루프에서 별도 검증이 필요하다.
선택 기준 3. 수정 전략과 diff 품질
좋은 에이전트는 한 번에 거대한 코드를 밀어 넣지 않는다. 작은 단위로 변경하고, 기존 구조를 보존하고, 컨트롤러나 CLI 같은 인터페이스 계층에 비즈니스 로직을 밀어 넣지 않는다. diff가 작고 리뷰 가능해야 한다.
이 기준에서는 “코드가 돌아간다”보다 “나중에 사람이 유지보수할 수 있다”가 중요하다. 테스트는 통과했지만 도메인 로직이 CLI에 섞였거나, 기존 파일을 필요 이상으로 갈아엎었다면 실무 점수는 낮다.
선택 기준 4. 테스트 실패 복구력
AI 코딩 에이전트의 진짜 실력은 첫 코드가 아니라 실패 후에 드러난다. 좋은 에이전트는 테스트 실패를 그대로 읽고, 실패한 assertion과 관련 파일을 좁히고, 원인을 가정한 뒤 최소 수정으로 다시 검증한다.
반대로 나쁜 패턴은 테스트를 느슨하게 바꾸거나, 실패 원인을 보지 않고 코드를 대량 재작성하거나, “통과했다”고 말하면서 실제 명령을 돌리지 않는 것이다. 코딩 에이전트를 평가할 때는 반드시 독립적인 스모크 테스트를 붙여야 한다.
선택 기준 5. 최종 보고서와 리뷰 가능성
실무에서는 결과 코드만큼 최종 보고서도 중요하다. 어떤 파일을 바꿨는지, 어떤 명령을 돌렸는지, 어떤 테스트가 통과했는지, 남은 리스크가 무엇인지가 명확해야 한다. 이 정보가 없으면 사람 리뷰어는 다시 처음부터 확인해야 한다.
좋은 보고서는 “완료했다”가 아니라 “무엇을 근거로 완료라고 판단했는지”를 보여준다. 예를 들어 npm run build, npm test, 별도 CLI smoke test, public URL 확인 같은 실제 명령 결과가 포함되어야 한다.
선택 기준 6. 생태계와 보안
MCP, 브라우저, 쉘, 클라우드 API를 붙이면 에이전트의 능력은 커진다. 동시에 위험도 커진다. 로컬 파일, GitHub 토큰, 클라우드 권한, 브라우저 세션이 에이전트 도구에 노출될 수 있기 때문이다.
따라서 “도구가 많다”는 장점이면서 리스크다. MCP 서버는 필요한 것만 연결하고, 쓰기 권한은 최소화하고, 결제·배포·삭제 같은 파괴적 작업은 사람이 확인하는 방식이 안전하다. 회사 코드에서는 오픈 모델 자체 호스팅 여부보다 권한 설계가 더 중요할 수 있다.
선택 기준 7. 비용, 속도, 반복 가능성
한 번 멋진 결과를 내는 것보다 매일 반복해서 쓸 수 있는지가 중요하다. 에이전트가 너무 비싸거나, 너무 느리거나, 자주 끊기면 팀의 기본 도구가 되기 어렵다. 반대로 약간 덜 똑똑해도 빠르고 저렴하며 안정적인 도구가 작은 작업에서는 더 유용할 수 있다.
Antigravity CLI처럼 Google 개인 무료 티어 흐름을 이어받는 도구는 조사·작은 수정·개인 자동화에 강점이 있다. Claude Code나 Codex는 더 복잡한 작업 루프에서 강점을 보일 수 있다. GLM 계열은 자체 배포와 비용 통제 가능성이 매력적이지만, 실제 운영 비용과 안정성은 별도 실험이 필요하다.
상황별 추천
| 상황 | 우선 검토할 선택지 | 이유 |
|---|---|---|
| 복잡한 백엔드 수정과 테스트 복구 | Claude Code, Codex | 장기 작업 루프와 테스트 기반 수정 흐름이 중요하다 |
| 터미널에서 빠르게 조사하고 작은 패치 | Antigravity CLI | 오픈소스 CLI, 웹 fetch, 검색 grounding, 접근성이 좋다 |
| 사내망·비용 통제·오픈 모델 실험 | GLM-5.2 계열 | 자체 호스팅 가능성과 오픈 모델 검토 가치가 있다 |
| GitHub 리뷰·자동 수정 루프 | Codex | OpenAI 개발자 생태계와 코드 에이전트 흐름을 같이 볼 수 있다 |
| 장문 정책 문서 기반 구현 | Claude Code, GLM 계열 실험 | 컨텍스트 관리와 정책 해석 능력을 함께 봐야 한다 |
평가 체크리스트
- 같은 저장소를 복사해 모델별 독립 워크스페이스를 만든다.
- 같은 프롬프트와 같은 문서 세트를 제공한다.
- 빌드, 테스트, lint 명령을 명확히 지정한다.
- 에이전트가 만든 자기 테스트와 별도 외부 스모크 테스트를 분리한다.
- 완료 시간, 중단 여부, 토큰/비용, 테스트 수, 최종 결함을 따로 기록한다.
- 최종 점수는 실행 안정성과 코드 품질을 분리해서 매긴다.
- 한 번의 결과로 모델 전체 우열을 단정하지 않는다.
결론
가격까지 포함하면 선택 기준은 더 현실적이다. AI 코딩 에이전트 선택의 핵심은 “어떤 모델이 가장 똑똑한가”가 아니다. 내 코드베이스에서 안전하게 도구를 쓰고, 실패를 복구하고, 테스트로 검증하고, 리뷰 가능한 diff를 남기는가다.
Claude Code, Codex, Antigravity CLI, GLM-5.2는 서로 다른 강점을 가진다. 따라서 실무에서는 하나를 절대 정답으로 고르기보다, 작업 유형별로 기본 도구와 보조 도구를 나누는 편이 현실적이다. 장기 구현은 안정적인 에이전트에 맡기고, 조사·작은 수정·오픈 모델 실험은 더 가볍고 저렴한 도구로 분리하는 식이다.
관련 글로는 GLM-5.2 vs Opus 4.8 코딩대결, GLM-5.2 총정리, AI 코딩 에이전트 비교 2026을 함께 보면 좋다.
공식 참고 자료
- Claude Code 공식 문서
- OpenAI Codex 개발자 페이지
- Google Code Assist / Antigravity 전환 안내
- Z.ai GLM GitHub
- Model Context Protocol 공식 문서
FAQ
AI 코딩 에이전트는 벤치마크 1등 모델을 고르면 되나?
아니다. 벤치마크는 참고 지표지만 실제 코딩 에이전트 품질은 도구 호출 안정성, 컨텍스트 관리, 테스트 실패 복구력, diff 품질, 비용과 속도에 따라 달라진다.
Claude Code, Codex, Antigravity CLI, GLM-5.2 중 하나만 추천한다면?
하나로 단정하기 어렵다. 안정적인 장기 작업은 Claude Code, OpenAI 생태계와 코드 리뷰 흐름은 Codex, 터미널 중심 Google 무료 티어 흐름은 Antigravity CLI, 오픈 모델·자체 호스팅 가능성은 GLM 계열이 강점이다.
AI 코딩 에이전트를 평가할 때 가장 중요한 기준은 무엇인가?
실무에서는 테스트 실패를 스스로 재현하고 고치는 능력, 작은 단위로 안전하게 수정하는 diff 품질, 최종 변경 사항을 사람이 리뷰하기 쉽게 설명하는 능력이 특히 중요하다.



