Agentic Resource Discovery, 줄여서 ARD는 AI 에이전트가 필요한 도구·스킬·API·다른 에이전트를 웹에서 찾고, 게시자를 검증한 뒤, 각 도구의 원래 방식으로 연결하게 돕는 개방형 발견 표준이다. 쉽게 말하면 “AI 에이전트용 검색 엔진과 사이트맵 사이의 표준”에 가깝다. Google Developers Blog는 2026년 6월 17일 Announcing the Agentic Resource Discovery specification 글에서 이 명세를 소개했다.
- ARD는 AI 에이전트가 외부 능력을 찾는 발견(discovery) 표준이다.
- MCP, A2A, OpenAPI 같은 실행·연결 방식 자체를 대체하지 않는다.
- 조직은
ai-catalog.json으로 자신이 제공하는 에이전트형 리소스를 설명한다. - 레지스트리는 여러 카탈로그를 크롤링·색인해 에이전트가 검색할 수 있게 만든다.
- 핵심 가치는 검색, 검증, 신뢰, 거버넌스를 런타임 연결 전 단계에 붙이는 데 있다.
왜 ARD가 필요한가
지금의 AI 에이전트는 혼자 모든 일을 처리하지 않는다. 코드를 고치려면 GitHub나 CI 도구를 부르고, 회사 데이터를 보려면 내부 API를 찾고, 일정이나 문서를 처리하려면 별도 서비스에 연결한다. 문제는 에이전트가 “어떤 도구가 있는지”, “그 도구가 내가 원하는 작업에 맞는지”, “연결해도 안전한지”를 공통 방식으로 알기 어렵다는 점이다.
사람은 검색엔진, 문서, 마켓플레이스, 사내 위키를 뒤져서 도구를 고른다. 반면 에이전트는 런타임에 기계가 읽을 수 있는 설명과 신뢰 정보를 받아야 한다. ARD는 이 빈칸을 메우려는 시도다. Google의 설명처럼 에이전트 생태계가 커지려면 “필요한 능력은 어디에 있는가, 무엇을 써야 하는가, 안전하게 연결해도 되는가”라는 질문에 안정적으로 답해야 한다.
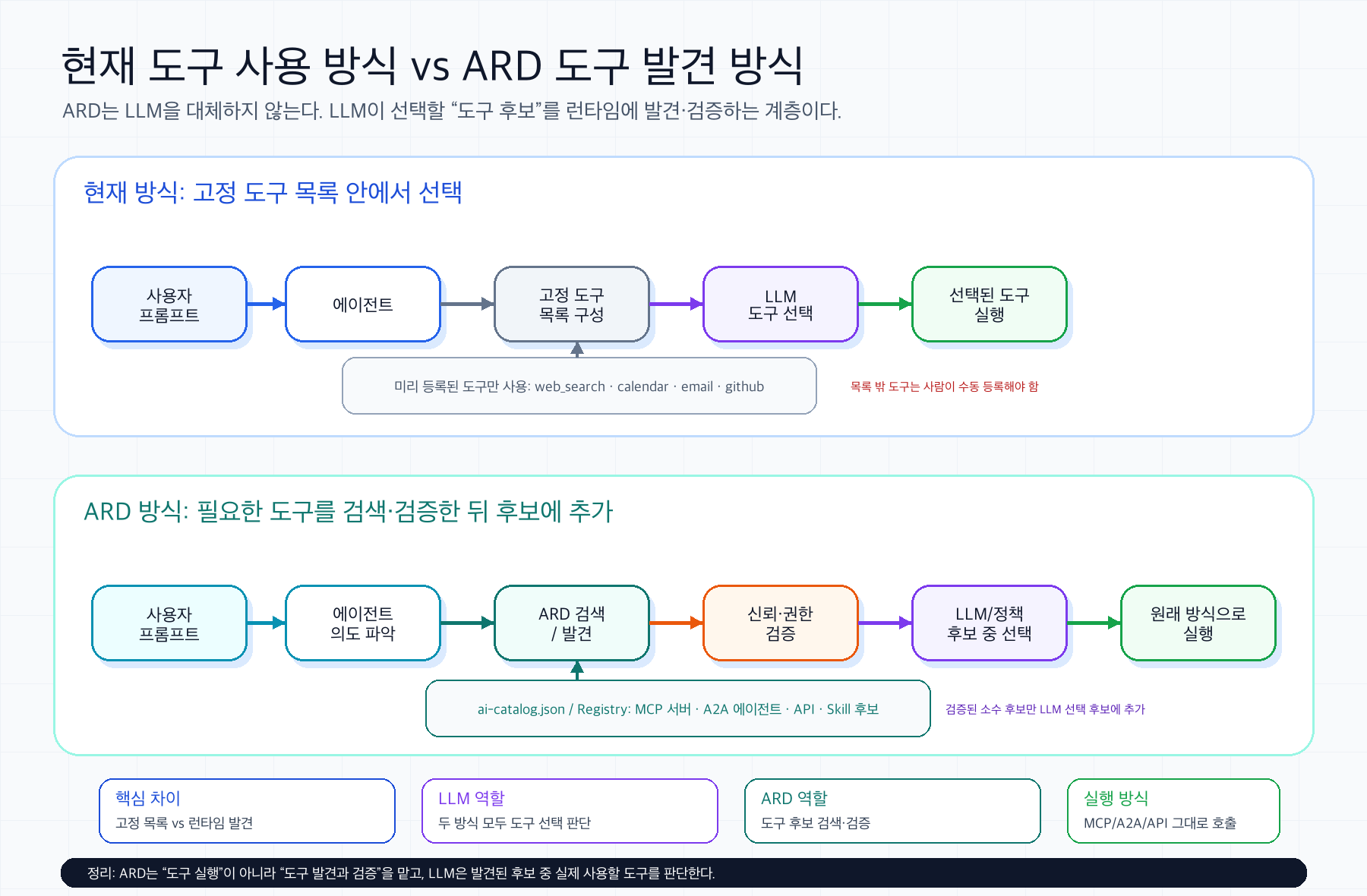
현재 도구 사용 방식과 ARD 방식의 차이
ARD를 이해할 때 가장 중요한 지점은 “LLM이 도구를 고른다”는 사실이 바뀌는 것이 아니라는 점이다. 차이는 LLM이나 에이전트가 선택할 도구 후보를 어디서 가져오느냐에 있다. 현재 방식은 미리 등록된 도구 목록 안에서 고르고, ARD 방식은 필요한 능력을 검색해 후보 도구를 동적으로 가져온다.
| 단계 | 현재 방식 | ARD 도입 후 |
|---|---|---|
| 1. 사용자 요청 | 사용자가 에이전트에게 작업을 요청한다. | 동일하게 사용자가 에이전트에게 작업을 요청한다. |
| 2. 도구 후보 준비 | 에이전트에 미리 등록된 고정 도구 목록만 사용한다. | 현재 도구로 부족하면 ARD 레지스트리에서 필요한 능력을 검색한다. |
| 3. 후보 범위 | web_search, calendar, email처럼 설정에 들어 있는 도구로 제한된다. | MCP 서버, A2A 에이전트, API, Skill, 워크플로까지 후보로 찾을 수 있다. |
| 4. 신뢰 확인 | 운영자가 수동으로 신뢰한 도구를 config/code에 넣는 방식이다. | 도메인 기반 카탈로그, 게시자 정보, trust metadata를 보고 검증할 수 있다. |
| 5. LLM 역할 | 고정 도구 목록 중 어떤 도구를 쓸지 판단한다. | ARD가 찾은 소수 후보까지 포함해 어떤 도구를 쓸지 판단한다. |
| 6. 실제 실행 | 선택된 기존 도구를 에이전트 런타임이 실행한다. | 선택된 리소스를 MCP, A2A, OpenAPI, 자체 API 등 원래 방식으로 호출한다. |
| 핵심 한계/효과 | 도구가 없으면 사람이 직접 등록해야 한다. | 필요한 도구를 런타임에 발견하고 후보에 추가할 수 있다. |
ARD를 한 문장으로 이해하기
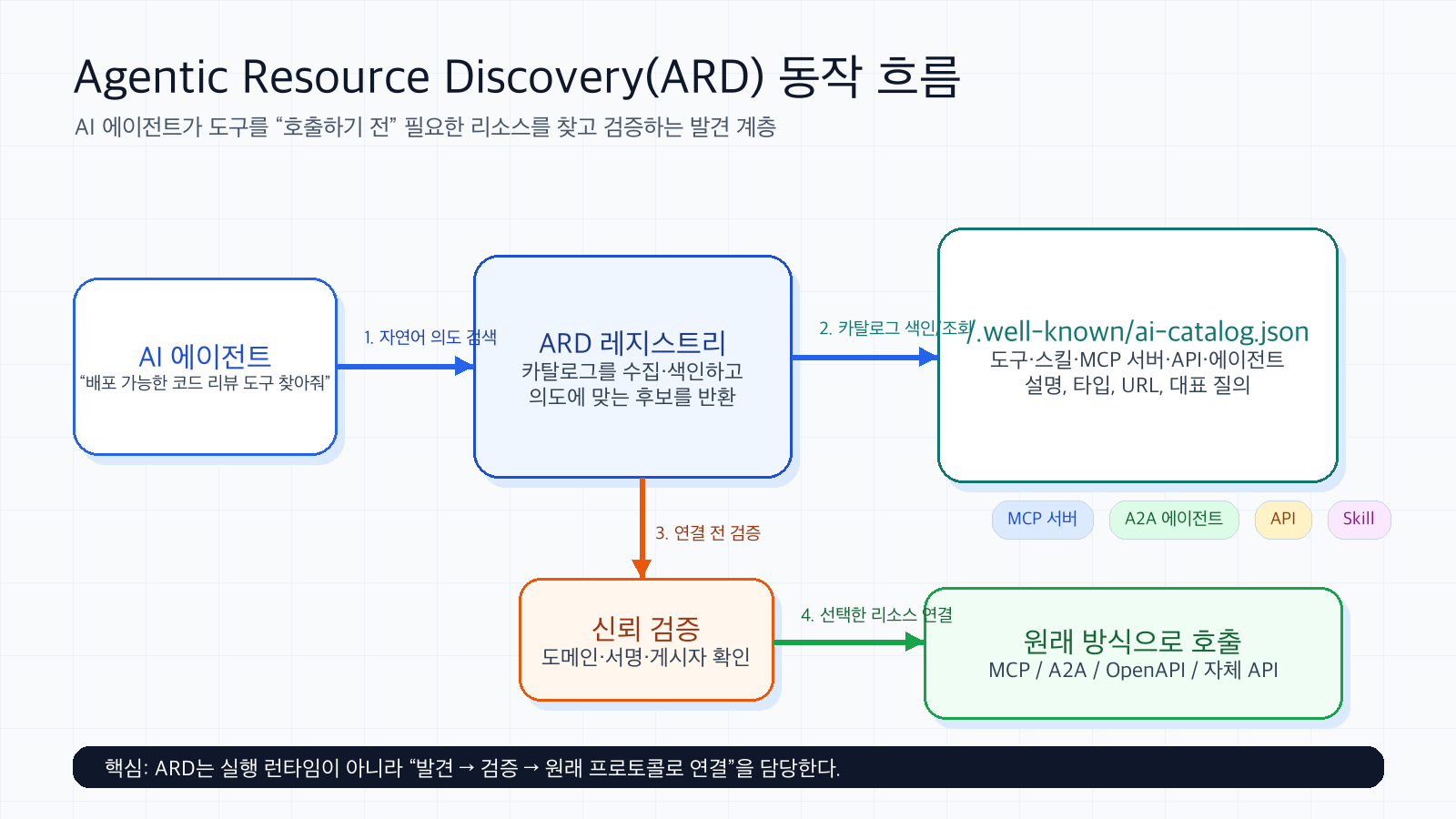
ARD는 AI 에이전트가 호출할 수 있는 리소스를 웹에 게시하고, 검색하고, 검증하기 위한 표준화된 발견 계층이다. 여기서 리소스는 단순한 웹페이지가 아니라 에이전트가 실제로 사용할 수 있는 능력이다. MCP 서버, A2A 에이전트 카드, 스킬, 플러그인, API, 워크플로가 모두 후보가 된다.
중요한 점은 ARD가 실행 런타임이 아니라는 사실이다. ARD는 “무엇을 찾을지”와 “어떻게 신뢰할지”를 다룬다. 실제 호출은 MCP면 MCP 방식으로, OpenAPI면 HTTP API 방식으로, A2A면 A2A 방식으로 이루어진다.
구성 요소: 카탈로그와 레지스트리
| 구성 요소 | 역할 | 웹에 비유하면 |
|---|---|---|
| Catalog | 조직이 제공하는 도구·에이전트·API 목록을 기계가 읽을 수 있게 설명한다. | sitemap.xml, llms.txt, API 문서의 중간 지점 |
| Registry | 여러 카탈로그를 수집·색인하고 에이전트의 검색 요청에 맞는 후보를 돌려준다. | 검색엔진 또는 사내 검색 인덱스 |
| Trust metadata | 게시자와 리소스의 신뢰성을 확인하기 위한 메타데이터를 제공한다. | 도메인 소유권, 서명, 출처 검증 |
| Native invocation | 발견 이후에는 각 도구의 원래 프로토콜로 호출한다. | MCP, A2A, OpenAPI, 자체 API |
공식 문서의 게시 가이드는 가장 단순한 시작점으로 /.well-known/ai-catalog.json 경로를 제시한다. 이 파일 안에는 호스트 정보와 리소스 목록이 들어간다. 각 리소스는 식별자, 표시 이름, 타입, URL, 기능, 설명, 대표 질의 같은 검색·매칭용 정보를 갖는다.
ai-catalog.json은 어떤 역할을 하나
ai-catalog.json은 사람이 읽는 소개 페이지가 아니라 에이전트와 레지스트리가 읽는 매니페스트다. 예를 들어 어떤 회사가 날씨 MCP 서버를 제공한다면 “이 서버는 날씨 조회와 예보 기능을 제공하고, 이런 자연어 질문에 적합하며, 이 URL에서 연결할 수 있다”는 정보를 JSON으로 공개한다.
{
"specVersion": "1.0",
"host": {
"displayName": "Acme Dev Tools",
"identifier": "did:web:acme.com"
},
"entries": [
{
"identifier": "urn:air:acme.com:server:weather",
"displayName": "Acme Weather Telemetry Server",
"type": "application/mcp-server+json",
"url": "https://api.acme.com/mcp/weather.json",
"capabilities": ["WeatherTool", "ForecastTool"],
"description": "Live weather telemetry MCP server",
"representativeQueries": [
"what is the current wind speed in Chicago",
"get the 5-day forecast for Seattle"
]
}
]
}이 예시는 공식 게시 가이드의 구조를 단순화한 것이다. 핵심은 대표 질의다. 검색엔진이 웹페이지의 제목과 본문을 색인하듯, ARD 레지스트리는 리소스 설명과 대표 질의를 이용해 “이 작업에는 어떤 능력이 맞는가”를 판단할 수 있다.
예제의 url은 최종 API endpoint가 아니다
위 예제에서 "url": "https://api.acme.com/mcp/weather.json"은 날씨 데이터를 바로 반환하는 최종 실행 API라고 보기보다, 해당 MCP 서버를 설명하는 artifact document의 위치로 보는 것이 정확하다. 에이전트나 레지스트리는 이 URL에서 weather.json을 가져와 실제 transport endpoint, tool schema, 인증 방식, 권한 범위 같은 연결 정보를 확인한다.
즉 ARD catalog entry의 url은 “이 도구를 실행하라”는 버튼이 아니라 “이 도구를 자세히 설명하는 문서를 여기서 가져가라”는 참조에 가깝다. 실제 호출은 그 문서 안에 정의된 MCP endpoint, A2A endpoint, OpenAPI servers와 paths, Skill package location 같은 정보를 따라 이루어진다.
| 구분 | 역할 | 예시 |
|---|---|---|
ai-catalog.json | 검색·발견용 상위 catalog | /.well-known/ai-catalog.json |
catalog entry의 url | 상세 artifact document 위치 | https://api.acme.com/mcp/weather.json |
| artifact document | 실제 연결 방식, schema, auth 설명 | MCP server card, OpenAPI spec, A2A agent card |
| 실제 실행 endpoint | 에이전트 런타임이 호출하는 대상 | https://api.acme.com/mcp/weather, OpenAPI path 등 |
OpenAPI 도구라면 catalog entry의 url은 보통 openapi.json을 가리키고, 실제 호출 경로는 그 문서 안의 servers와 paths에 정의된다. MCP 도구라면 url이 MCP 서버 카드나 descriptor를 가리키고, 실제 MCP 연결 endpoint는 그 descriptor 안에서 확인하는 구조가 된다.
MCP, A2A, llms.txt와 무엇이 다른가
| 개념 | 주요 질문 | ARD와의 관계 |
|---|---|---|
| MCP | 도구를 어떤 프로토콜로 호출할 것인가 | ARD가 MCP 서버를 발견할 수 있다. MCP 자체를 대체하지 않는다. |
| A2A | 에이전트끼리 어떻게 협업할 것인가 | ARD가 A2A 에이전트 카드를 발견 대상으로 다룰 수 있다. |
| llms.txt | LLM에게 사이트의 핵심 문서와 읽을거리를 어떻게 안내할 것인가 | 둘 다 AI가 읽기 좋은 공개 메타데이터라는 흐름을 공유한다. |
| ARD | 에이전트가 사용할 수 있는 능력은 어디에 있고, 신뢰할 수 있는가 | 실행 전 발견·검색·검증 계층이다. |
따라서 ARD를 “MCP 다음 버전”으로 보면 헷갈린다. 더 정확한 비유는 “MCP 서버와 여러 에이전트형 리소스를 검색 가능하게 만드는 발견 표준”이다. MCP가 전원 플러그와 콘센트의 규격이라면, ARD는 “어느 방에 어떤 콘센트가 있고, 누가 관리하며, 안전한가”를 알려주는 지도에 가깝다.
이 관점은 기존에 다룬 llms.txt 작성 방법, AI 검색 최적화 GEO, AI 코딩 에이전트 선택 기준과도 이어진다. 웹이 사람을 위한 페이지 중심에서 AI가 직접 읽고 호출하는 리소스 중심으로 확장되는 흐름이다.
개발자와 사이트 운영자는 무엇을 봐야 하나
- 내 사이트가 제공하는 능력을 목록화한다. 단순 글이 아니라 API, 계산기, MCP 서버, 워크플로, 자동화 기능처럼 에이전트가 호출할 수 있는 것을 정리한다.
- 기계가 읽을 설명을 준비한다. 이름, 타입, URL, 기능, 대표 질의, 제한사항을 사람용 마케팅 문구가 아니라 검색·매칭용 메타데이터로 쓴다.
- 도메인 기반 신뢰를 설계한다. 공식 도메인 아래에 카탈로그를 두면 “누가 이 리소스를 게시했는가”를 확인하기 쉬워진다.
- 호출 프로토콜을 분리해서 생각한다. ARD는 찾는 표준이고, MCP·A2A·OpenAPI는 연결하거나 호출하는 방식이다.
- 공개 웹과 사내망을 나눠 설계한다. 공개 검색 가능한 리소스와 사내 에이전트만 써야 하는 리소스는 서로 다른 레지스트리 정책이 필요하다.
GEO 관점에서 ARD가 중요한 이유
GEO, 즉 생성형 검색 최적화는 AI가 사이트의 내용을 이해하고 인용하거나 추천할 수 있게 만드는 작업이다. ARD는 전통적인 글 인용보다 한 단계 더 나아간다. AI가 문서를 읽는 데서 끝나는 것이 아니라, 실제 기능을 발견하고 연결할 수 있는 구조를 다루기 때문이다.
물론 ARD 파일을 둔다고 Google AI Overview나 ChatGPT에 바로 노출되는 것은 아니다. 공식 문서도 특정 레지스트리가 반드시 색인한다고 보장하지 않는다. 다만 방향성은 분명하다. 앞으로의 웹에서는 “사람이 읽는 본문”, “검색엔진이 읽는 구조화 데이터”, “LLM이 읽는 안내 파일”, “에이전트가 호출 가능한 리소스 카탈로그”가 함께 필요해질 가능성이 높다.
ARD의 현재 상태와 한계
GitHub 저장소 기준 ARD 명세는 v0.9 초안 상태다. Apache 2.0 라이선스로 공개되어 있고, AI Catalog 데이터 모델 위에 구축된다. 이는 지금 당장 모든 사이트가 필수로 도입해야 하는 완성 표준이라는 뜻이 아니다. 오히려 에이전트 생태계가 어떤 방향으로 표준화될지 보여주는 초기 신호로 보는 편이 적절하다.
또 하나의 한계는 중앙 검색엔진이 하나로 정해지는 구조가 아니라는 점이다. ARD 문서는 여러 발견 서비스가 각자 다른 리소스를 색인하고, 각자의 신뢰·랭킹·접근 정책을 적용할 수 있다고 설명한다. 공개 웹에는 여러 검색엔진이 있고, 회사 내부에는 사내 검색이 따로 있는 것과 비슷하다.
짧은 결론
ARD는 “AI 에이전트가 도구를 어떻게 호출하느냐”보다 “AI 에이전트가 쓸 만한 도구를 어떻게 찾고 믿느냐”에 초점을 둔 표준이다. MCP, A2A, OpenAPI가 에이전트 생태계의 연결 규격이라면, ARD는 그 연결 대상을 발견하는 검색·검증 계층이다. 아직 초안 단계지만 AI 검색, GEO, MCP, 에이전트 플랫폼을 다루는 개발자라면 지금부터 개념을 잡아둘 만하다.
FAQ
Agentic Resource Discovery는 무엇인가
AI 에이전트가 사용할 수 있는 도구, 스킬, MCP 서버, API, 다른 에이전트를 찾고 검증하기 위한 개방형 발견 명세다.
ARD는 MCP를 대체하나
대체하지 않는다. MCP는 호출·연결 프로토콜이고, ARD는 호출 전에 리소스를 찾고 검증하는 발견 계층이다.
ARD를 적용하려면 무엇부터 해야 하나
공개하거나 내부에서 검색 가능하게 만들 리소스를 정리하고, ai-catalog.json 매니페스트로 설명하는 것부터 시작한다. 공개 웹에서는 /.well-known/ai-catalog.json 경로가 기본 출발점이다.
ARD가 SEO 순위에 직접 영향을 주나
현재 기준으로 직접적인 SEO 순위 요소라고 볼 근거는 부족하다. 다만 AI가 사이트의 리소스와 기능을 이해하는 표준화 흐름이라는 점에서 GEO 전략과 함께 볼 가치가 있다.
공식 출처와 참고 링크
- Google Developers Blog: Announcing the Agentic Resource Discovery specification
- Agentic Resource Discovery 공식 문서
- ARD How to publish 가이드
- ards-project/ard-spec GitHub 저장소
- AI Catalog GitHub 저장소




