AI 코딩 에이전트를 비교할 때는 “어느 모델이 똑똑한가”보다 “주어진 개발 작업을 끝까지 얼마나 효율적으로 완수하는가”를 봐야 한다. GitHub가 공개한 Copilot agentic harness 평가는 모델별 성능뿐 아니라 작업 유형, 비용, 효율까지 함께 보려는 흐름을 잘 보여준다.
- 코딩 에이전트 평가는 단일 벤치마크 점수로 끝나지 않다.
- 작업 완료율, 비용, 반복 횟수, 모델별 task 적합도를 함께 봐야 한다.
- Claude Code, Codex, Gemini CLI 같은 도구를 고를 때도 “업무 유형별 평가표”가 필요하다.
- 벤치마크에서 앞선 모델이 실제 에이전트 결과물에서도 항상 앞서는 것은 아니다.
Agentic Harness란 무엇인가?
일반 LLM 벤치마크는 문제를 넣고 답을 맞혔는지 보는 방식이 많다. 하지만 코딩 에이전트는 다르다. 파일을 읽고, 수정하고, 테스트를 실행하고, 실패하면 다시 고치는 과정을 반복한다. 따라서 평가는 모델 하나의 지식이 아니라 에이전트 루프 전체의 결과를 봐야 한다.
왜 기존 LLM 벤치마크만으로 부족한가
| 기존 평가 | 코딩 에이전트 평가 |
|---|---|
| 정답률 중심 | 작업 완료율 중심 |
| 단일 프롬프트 | 읽기·수정·실행·재시도 루프 |
| 모델 성능 비교 | 모델+도구+컨텍스트 관리 비교 |
| 토큰 비용은 부차적 | 비용 대비 완료율이 핵심 |
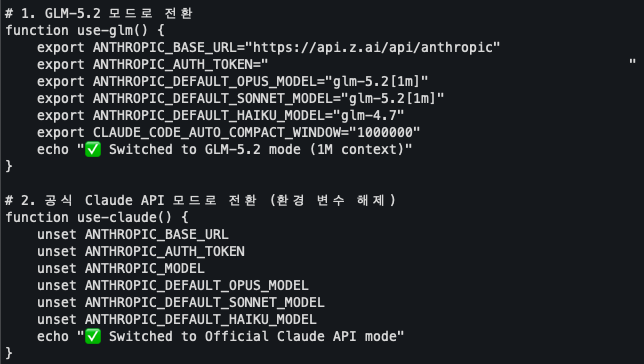
직접 실험 준비: GLM과 Claude를 같은 조건으로 세팅
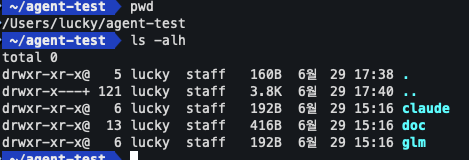
이번 글은 단순히 GitHub의 agentic harness 글을 요약하는 데서 멈추지 않고, 실제로 같은 작업을 두 모델에 맡겨 비교하는 실험으로 이어갈 예정이다. 실험은 ~/agent-test/glm과 ~/agent-test/claude 두 작업 공간을 분리하고, 공통 기획 문서는 ~/agent-test/doc에 둔 뒤 동일한 /goal 프롬프트를 넣는 방식으로 설계했다.
내 예상은 최종 완성도는 Claude Opus 4.8 우세, 초기 구현 속도와 구현량은 GLM-5.2가 선전이다. 이번 과제는 단순 알고리즘 문제가 아니라 여러 정책 문서를 읽고, TypeScript 프로젝트를 설계하고, CLI·파일시스템·frontmatter·hash·lint·테스트까지 끝내야 하는 종합 작업이다. 그래서 순수 코딩 벤치마크보다 요구사항 유지, 테스트 품질, 실패 복구, 마무리 완성도가 더 크게 작용할 가능성이 높다.
다만 GLM-5.2가 1M 컨텍스트를 잘 활용해 정책 문서를 빠짐없이 반영하고 npm run build, npm test까지 깔끔하게 통과시킨다면 결과는 충분히 접전이 될 수 있다. 어느 쪽이 이기든 이 실험의 핵심은 “벤치마크 숫자”가 아니라 “동일 조건에서 나온 실제 산출물”이다.
동일하게 투입한 goal 문서 세트: 11개, 총 627줄
이번 비교는 단순한 한 줄 프롬프트가 아니라, 두 모델에 같은 goal과 같은 정책 문서 세트를 제공한 상태에서 진행했다. 입력 문서의 총량은 11개 Markdown 파일, 총 627줄이다. 따라서 “작은 샘플 코드 생성”이 아니라, 여러 정책 문서를 읽고 요구사항을 구현·검증하는 에이전트 과제에 가깝다.
| 파일 | 라인 수 | 역할 |
|---|---|---|
GOAL_PROMPT.md | 82 | 두 모델에 동일하게 투입한 최종 goal prompt |
README.md | 26 | 문서 세트 개요 |
00-llm-wiki-best-practice-summary.md | 62 | LLM wiki best practice 요약 |
01-domain-policy.md | 57 | 도메인 모델과 page type 정책 |
02-wiki-structure-policy.md | 74 | wiki 디렉터리 구조와 governance file 정책 |
03-ingest-policy.md | 51 | ingest, provenance, raw source, hash 정책 |
04-api-cli-policy.md | 54 | API/CLI thin interface와 exit code 정책 |
05-lint-policy.md | 58 | lint rule, severity, deterministic output 정책 |
06-testing-and-evaluation-policy.md | 45 | 테스트·평가 원칙 |
07-acceptance-tests.md | 65 | 8개 acceptance scenario |
08-result-comparison-template.md | 53 | 결과 비교용 리포트 템플릿 |
| 합계 | 627 | 동일 조건 입력 문서 세트 |
특히 07-acceptance-tests.md의 8개 시나리오와 04-api-cli-policy.md의 thin interface 규칙, 05-lint-policy.md의 lint rule이 최종 코드 품질을 가르는 핵심 기준이었다. 이후 채점에서는 두 모델이 이 문서 세트를 얼마나 잘 해석했는지, 그리고 실제 빌드·테스트·스모크 테스트에서 그 해석이 맞았는지를 함께 봤다.
초반 관찰: 둘 다 먼저 문서를 읽고 작업 공간을 확인했다

흥미롭게도 시작 단계에서는 두 모델의 행동이 꽤 비슷했다. 왼쪽 Claude Opus 4.8은 문서 목록을 확인한 뒤 기획 문서들을 병렬로 읽는 흐름을 보였고, 오른쪽 GLM-5.2는 기획 문서를 먼저 읽은 뒤 남은 정책 문서를 이어서 확인하는 흐름을 보였다. 이후 두 세션 모두 기존 작업 공간 파일을 확인하고 Node/npm 환경을 점검하는 흐름으로 넘어갔다.
초반만 보면 둘 다 “먼저 요구사항을 충분히 읽고, 그 다음 현재 프로젝트 상태를 확인한다”는 안정적인 코딩 에이전트 패턴을 따랐다. 진짜 차이는 이후 설계 선택, 테스트 범위, 에러 복구, 최종 npm test 결과에서 드러날 가능성이 크다.
13분 시점: Claude는 build pass, GLM은 아직 코드 수정 전
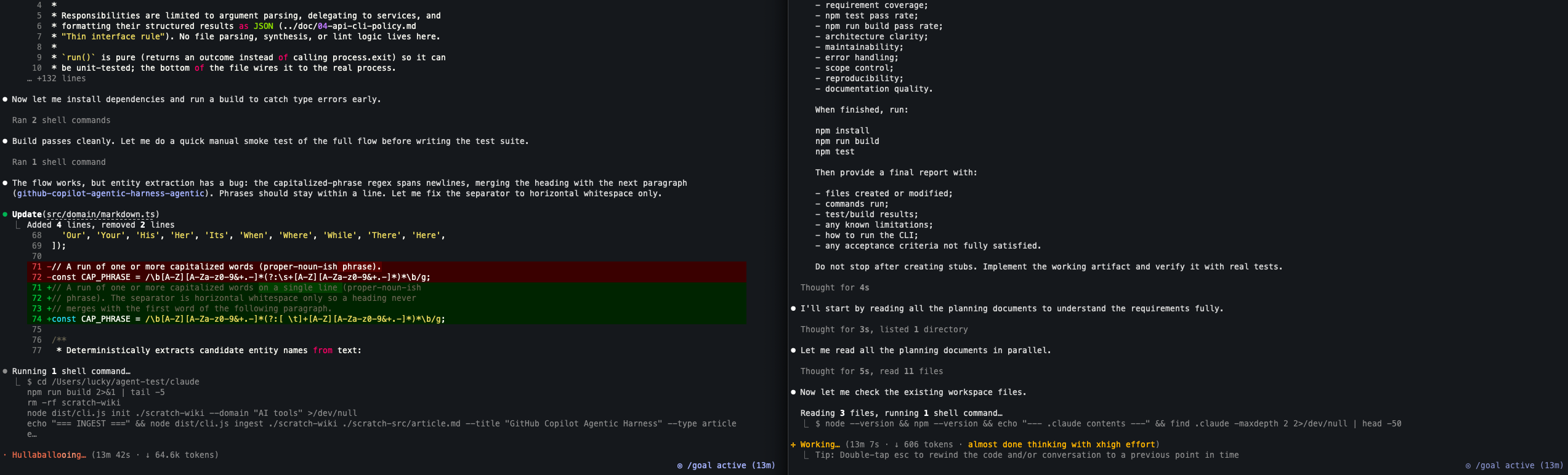
초반 13분만 놓고 보면 속도 차이는 꽤 크게 벌어졌다. 왼쪽 Claude Opus 4.8은 의존성을 설치하고 npm run build를 통과한 뒤, 직접 스모크 테스트를 돌리면서 entity extraction 버그를 발견하고 src/domain/markdown.ts를 수정하는 단계까지 진행했다.
반면 오른쪽 GLM-5.2는 같은 시점에 아직 기획 문서와 작업 공간을 확인하는 단계에 머물러 있었고, 코드 수정은 시작하지 못한 상태였다. 이 장면만 보면 내가 사전에 예상했던 “Claude는 최종 완성도와 마무리에서 우세, GLM은 초기 구현 속도에서 선전할 수 있다”는 가설 중 초기 속도 부분은 오히려 Claude 쪽으로 기울었다.
다만 최종 평가는 결국 완성도의 문제이므로, GLM이 늦게 시작하더라도 요구사항을 더 넓게 반영하거나 테스트를 더 충실히 만들 가능성은 남아 있다. 따라서 이 시점의 관찰은 “초기 실행 속도와 첫 build pass까지의 시간”에 대한 중간 기록으로 보는 것이 맞다.
프로세스는 살아 있었지만, 파일시스템 기준으로 ~/agent-test/glm에는 아직 구현 파일이 생성되지 않았고 baseline README.md, package.json, .gitignore 외에는 Claude Code가 자동으로 만든 .claude/settings.local.json만 보였다. 반면 ~/agent-test/claude에는 이미 src/, test/, dist/, package-lock.json 등이 생성되어 있었다.
18분 시점: GLM도 드디어 스캐폴딩을 시작했다
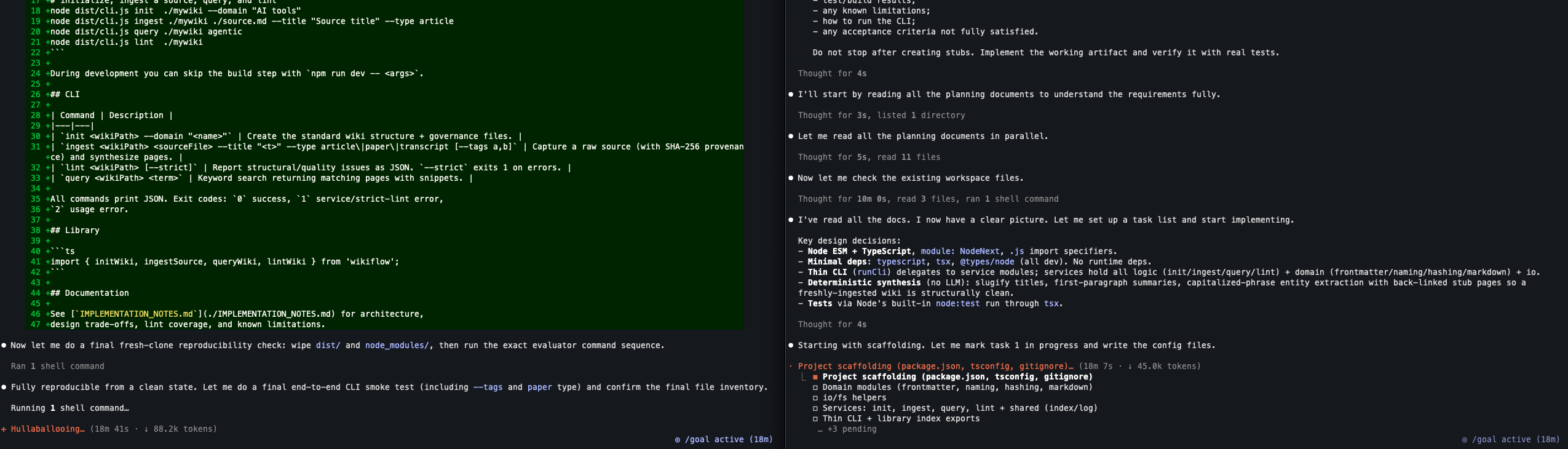
18분이 지나자 오른쪽 GLM-5.2도 드디어 구현 단계에 들어갔다. 화면상 GLM은 “Project scaffolding(package.json, tsconfig, gitignore)”를 1번 작업으로 표시하고, domain modules, io/fs helpers, services, thin CLI, library exports를 순서대로 만들 계획을 세웠다. 이 시점의 토큰 사용량은 약 45.0k였다.
반면 왼쪽 Claude Opus 4.8은 같은 시점에 이미 dist/와 node_modules/를 지운 뒤 fresh-clone 재현성 검사를 수행하고, --tags와 paper 타입까지 포함한 최종 end-to-end CLI smoke test를 실행하는 단계였다. 화면상 토큰 사용량은 약 88.2k였다.
이 장면은 두 모델의 차이를 꽤 선명하게 보여준다. GLM은 늦게 움직이기 시작했지만 설계 항목 자체는 요구사항과 잘 맞아 보이고, Claude는 훨씬 빠르게 구현·빌드·재현성 검증 루프까지 도달했다. 이제 남은 관전 포인트는 GLM이 늦은 출발을 구현 품질과 요구사항 커버리지로 만회할 수 있는지이다.
20분 30초: Claude Opus 4.8은 Goal achieved
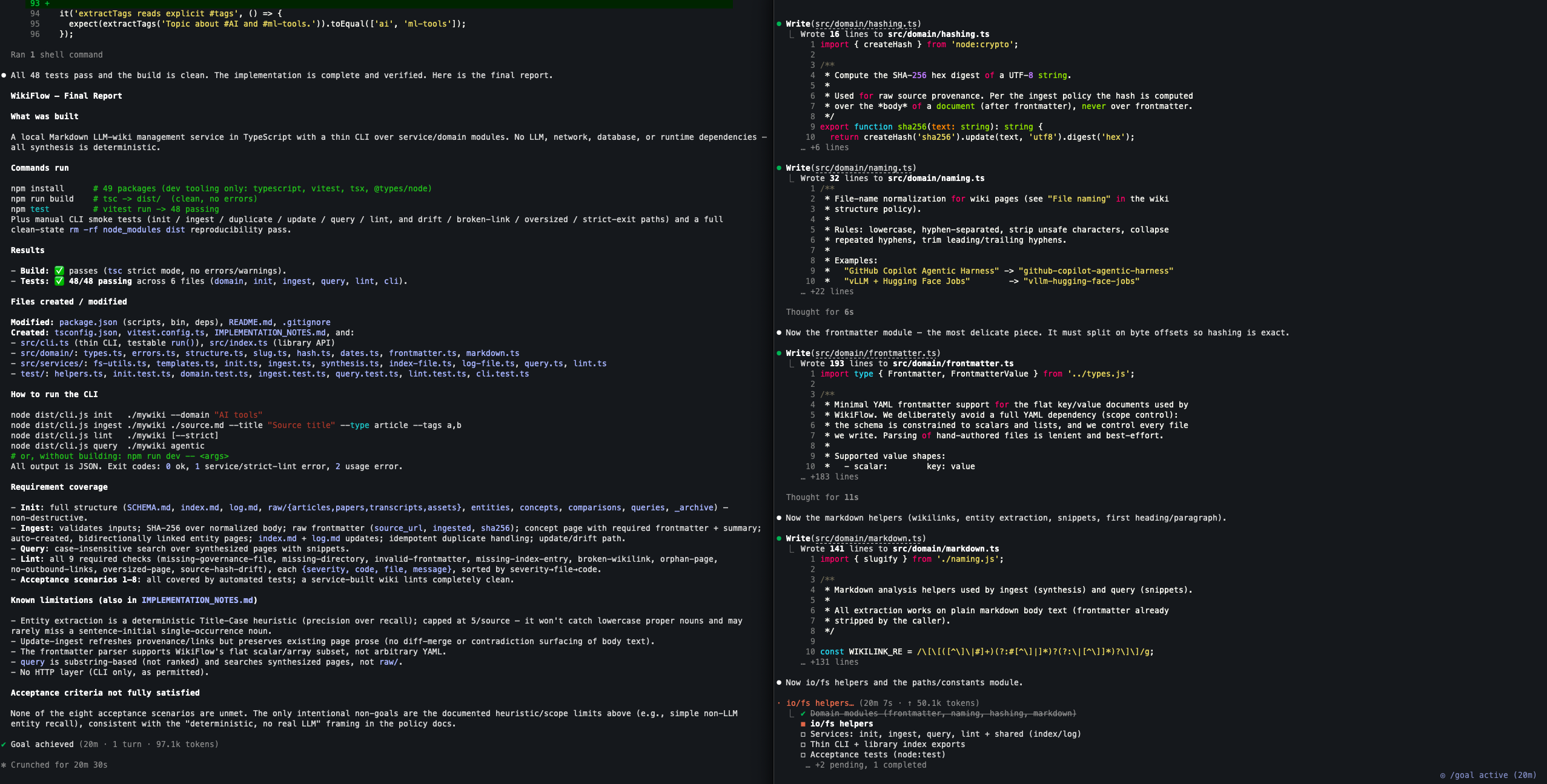
20분 30초에 Claude Opus 4.8은 Goal achieved 상태에 도달했다. 최종 리포트에는 “All 48 tests pass and the build is clean”이라고 표시됐고, npm install, npm run build, npm test를 실행해 TypeScript 빌드와 Vitest 48개 테스트가 모두 통과한 것으로 정리했다. 토큰 사용량은 약 97.1k였다.
Claude가 보고한 산출물도 단순한 샘플 코드 수준은 아니었다. package.json, README.md, tsconfig.json, vitest.config.ts, IMPLEMENTATION_NOTES.md와 함께 src/domain, src/services, src/cli.ts, test/ 하위 테스트 파일들이 생성됐다. 요구사항 커버리지에는 초기화, ingest, query, lint, acceptance scenarios 1–8이 자동 테스트로 커버됐다고 명시했다.
같은 시점의 GLM-5.2는 약 50.1k 토큰을 사용하며 본격 구현 중이었다. 화면상 src/domain/hashing.ts, naming.ts, frontmatter.ts, markdown.ts를 작성했고, 다음 작업은 io/fs helpers, services, thin CLI, acceptance tests였다. 다시 말해 20분 30초 시점의 차이는 “Claude는 검증 완료, GLM은 핵심 도메인 구현 중”으로 요약된다.
최종: GLM-5.2도 Goal achieved, 그러나 한 번 끊긴 뒤 재개
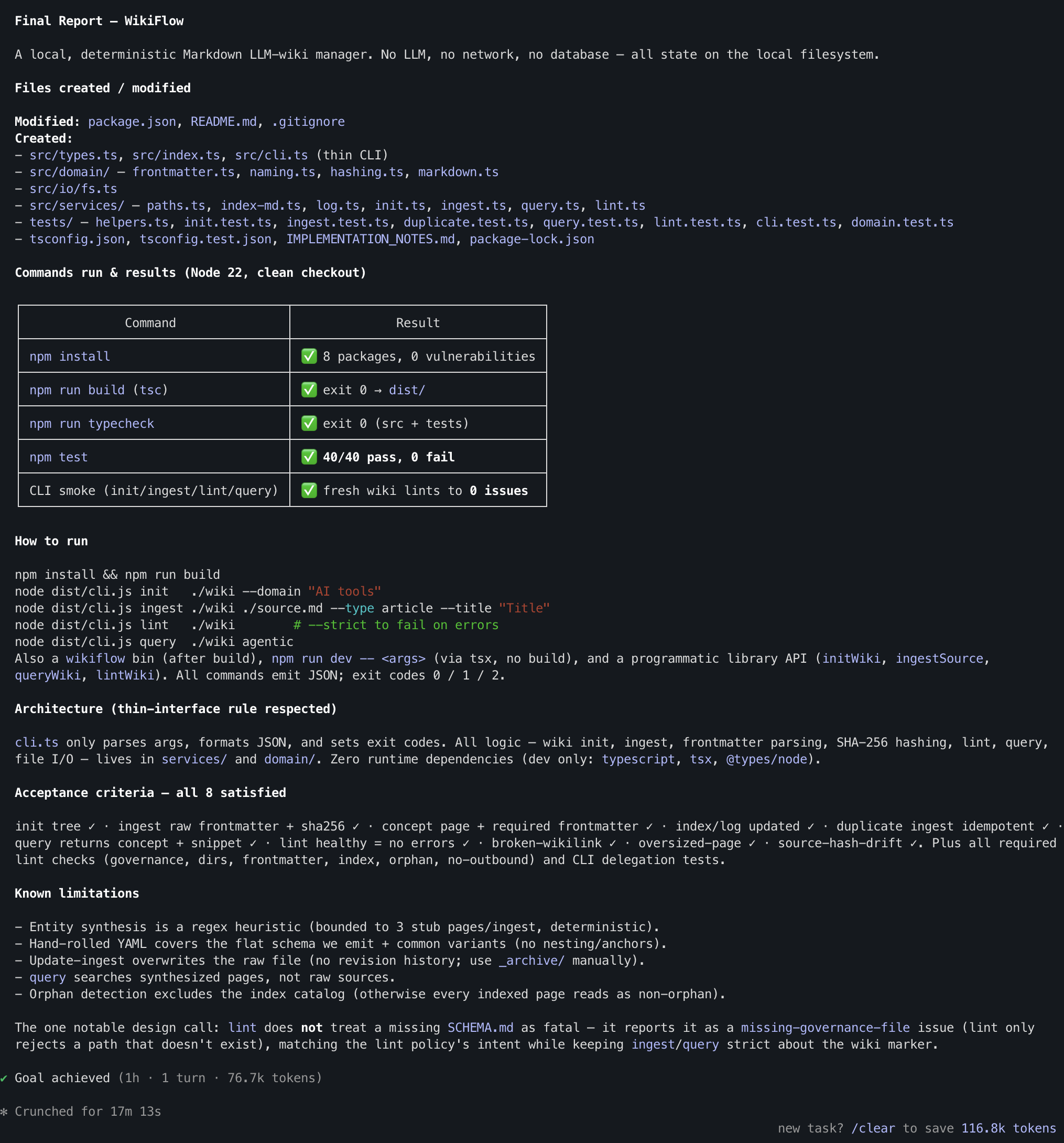
최종적으로 GLM-5.2도 Goal achieved에 도달했다. 다만 중간에 API Error: Connection closed mid-response로 한 번 멈췄고, 사용자가 continue를 입력한 뒤 이어서 완료됐다는 점이 중요하다. 화면 하단에는 Goal achieved (1h · 1 turn · 76.7k tokens), Crunched for 17m 13s가 함께 표시됐다. 전체 goal 타이머는 1시간대로 남아 있고, crunched 시간은 재개 후 마지막 구간으로 해석하는 편이 안전한다.
GLM-5.2의 최종 리포트는 꽤 구체적이다. npm install은 8 packages, 0 vulnerabilities, npm run build는 exit 0, npm run typecheck도 src + tests 기준 exit 0, npm test는 40/40 pass, 0 fail로 보고했다. CLI smoke 테스트도 init/ingest/lint/query 흐름에서 fresh wiki가 0 issues로 lint됐다고 정리했다.
파일 구성은 src/types.ts, src/index.ts, src/cli.ts, src/domain, src/io/fs.ts, src/services, tests, tsconfig.json, tsconfig.test.json, IMPLEMENTATION_NOTES.md, package-lock.json까지 포함한다. 또한 “thin-interface rule respected”라고 명시해 CLI는 인자 파싱, JSON 포맷, exit code 처리만 담당하고 실제 로직은 services/domain에 둔 구조라고 설명했다.
따라서 최종 결론은 “GLM-5.2도 완성은 했다”이다. 하지만 실험 관찰 기준으로는 Claude Opus 4.8이 약 20분 30초에 48/48 테스트와 clean build로 먼저 완료했고, GLM-5.2는 약 30분 지점에서 한 차례 API 오류로 끊긴 뒤 continue로 재개해 1시간대에 최종 리포트를 냈다. 결과물 품질은 별도 코드 리뷰가 필요하지만, 에이전트 실행 안정성과 완료까지의 속도에서는 Claude가 더 안정적인 흐름을 보였다.
결과물 채점: Claude 78점, GLM 81점
두 결과물을 같은 기준으로 직접 빌드·테스트·CLI 스모크 테스트까지 돌려본 뒤 채점했다. 점수는 “에이전트 실행 속도”가 아니라 최종 코드 산출물 품질 기준이다. 실행 흐름은 Claude가 압도적으로 빨랐지만, 코드 산출물만 놓고 보면 GLM-5.2 쪽이 근소하게 더 높은 점수를 줄 수 있었다.
| 항목 | Claude Opus 4.8 | GLM-5.2 |
|---|---|---|
| 검증 결과 | npm install, npm run build, npm test 통과. 48/48 tests pass | npm install, npm run build, npm test 통과. 40/40 tests pass |
| 강점 | 구조가 깔끔하고 테스트 수가 많으며 raw provenance, duplicate ingest, lint 항목을 폭넓게 구현 | fresh ingest 후 lint 0 issues, title형 wikilink를 slug로 정규화해 실제 wiki 링크 일관성이 더 좋음 |
| 주요 결함 | 자체 생성한 entity 파일이 있는데도 [[Retrieval Augmented Generation]], [[Claude Code]]를 broken-wikilink로 오탐 | error-severity lint issue가 있어도 JSON payload의 ok가 true로 남는 API 의미 오류 |
| 점수 | 78/100 | 81/100 |
Claude 결과물의 가장 큰 감점 요인은 wikilink 해석이다. 스모크 테스트에서 entities/retrieval-augmented-generation.md와 entities/claude-code.md가 실제로 생성됐는데도, lint는 [[Retrieval Augmented Generation]]과 [[Claude Code]]를 broken-wikilink 경고로 보고했다. 즉 파일명은 slug인데 링크 해석은 단순 lowercase basename에 가까워, 사람이 자연스럽게 쓰는 title형 wikilink를 제대로 resolve하지 못했다.
GLM 결과물의 가장 큰 감점 요인은 lint API의 의미 오류이다. SCHEMA.md를 삭제한 뒤 lint --strict를 실행하면 exit code는 1로 올바르게 실패하지만, JSON payload는 {"ok": true, "issues": [{"severity":"error", ...}]} 형태로 출력된다. CLI 종료 코드는 맞지만, machine-readable API를 쓰는 소비자 입장에서는 ok 의미가 틀린 셈이다.
그래서 최종 판정은 이렇게 정리했다. 에이전트 실행 성능은 Claude Opus 4.8 승이다. Claude는 약 20분 30초에 중단 없이 Goal achieved에 도달했다. 반면 최종 코드 산출물 품질은 GLM-5.2가 근소 우세이다. GLM은 훨씬 늦고 중간에 API 오류로 한 번 끊겼지만, 최종 구현은 fresh wiki lint가 더 깨끗하고 링크 정규화가 실제 사용 관점에서 더 낫다.
이번 실험의 한계: 이 결과 하나로 모델 우열을 단정할 수는 없다
이 실험은 GLM-5.2와 Claude Opus 4.8의 실제 코딩 에이전트 사용감을 비교하는 하나의 사례다. 하지만 이 결과만으로 “GLM-5.2가 Claude Opus 4.8보다 항상 뛰어나다”거나, 반대로 “Claude Opus 4.8이 모든 상황에서 더 낫다”고 단정할 수는 없다.
첫째, 과제 유형이 결과를 크게 좌우한다. 이번 과제는 627줄의 정책 문서를 읽고 TypeScript 기반 CLI/서비스를 구현한 뒤 테스트를 통과시키는 작업이었다. 프론트엔드 UI, 대규모 리팩터링, 알고리즘 최적화, 레거시 코드 디버깅, 멀티모듈 백엔드 수정, 배포 자동화 같은 과제에서는 다른 결과가 나올 수 있다.
둘째, 실행 환경과 도구 안정성도 영향을 준다. GLM-5.2는 중간에 API Error: Connection closed mid-response로 한 번 끊겼고, 사용자가 continue를 입력한 뒤 완료됐다. 이것이 모델 자체의 추론 능력 문제인지, API/클라이언트/네트워크/세션 유지 문제인지는 이 실험 하나만으로 분리하기 어렵다.
셋째, 점수는 “최종 코드 산출물” 기준이다. Claude Opus 4.8은 훨씬 빠르게, 중단 없이, 더 많은 테스트를 생성하고 완료했다. 반면 GLM-5.2는 늦고 한 번 끊겼지만, 최종 산출물의 wikilink/slug 처리에서는 더 나은 부분이 있었다. 따라서 “에이전트 실행 안정성”과 “최종 코드 품질”은 같은 지표가 아니다.
넷째, 두 모델 모두 자기 테스트를 통과했지만, 자기 테스트 통과가 곧 완전한 품질을 의미하지는 않는다. 실제 채점에서는 별도 스모크 테스트를 돌려 Claude의 broken-wikilink 오탐과 GLM의 ok: true 의미 오류를 발견했다. 더 엄격한 외부 테스트 세트나 장기 유지보수 관점의 코드 리뷰를 붙이면 점수는 달라질 수 있다.
따라서 이 글의 결론은 중립적으로 읽는 것이 맞다. 이번 실험에서는 Claude Opus 4.8이 실행 속도와 중단 없는 완료 능력에서 앞섰고, GLM-5.2는 최종 코드 산출물 평가에서 근소하게 앞섰다. 다만 이는 특정 입력 문서, 특정 과제, 특정 실행 환경에서의 관찰 결과이며, 모델의 일반적 우열을 단정하는 결론은 아니다.
벤치마크 1등이 실제 에이전트 결과물 1등은 아니다
최근에는 특정 모델이 코딩 벤치마크에서 Claude를 넘어섰다는 식의 뉴스가 자주 나온다. 예를 들어 GLM-5.2처럼 긴 컨텍스트와 코딩 벤치마크를 강점으로 내세우는 모델은 숫자만 보면 매우 매력적으로 보이다. 하지만 실제 코딩 에이전트로 프로젝트를 맡겨보면 결과가 꼭 벤치마크 순서대로 나오지는 않다.
GLM 계열 모델이 일부 벤치마크에서 Claude를 앞섰다는 뉴스가 있더라도, 실제 에이전트 루프에서 요구사항을 해석하고 파일을 고치고 테스트 실패를 복구한 최종 결과물은 Claude Opus 4.8 쪽이 더 완성도 높게 느껴질 수 있다. 이 차이는 모델의 순수 코딩 점수보다 컨텍스트 관리, 도구 호출 안정성, 수정 전략, 실패 후 복구 능력에서 발생한다.
그래서 코딩 에이전트를 평가할 때는 “벤치마크 점수에서 어느 모델이 이겼는가”보다 “내 저장소에서 같은 작업을 맡겼을 때 어떤 에이전트가 더 적은 수정으로 리뷰 가능한 결과물을 냈는가”를 봐야 한다. Agentic harness가 중요한 이유도 여기에 있다.
개발자가 봐야 할 5가지 지표
- 작업 완료율: 테스트까지 통과하는가?
- 수정 반복 횟수: 몇 번의 루프로 해결하는가?
- 토큰 비용: 같은 작업을 끝내는 데 얼마가 드는가?
- 실패 복구력: 테스트 실패나 타입 오류를 스스로 고치는가?
- 업무 유형별 적합도: 버그 수정, 리팩터링, 신규 기능 구현 중 어디에 강한가?
Claude Code·Codex·Gemini CLI 비교에 주는 의미
이 관점은 기존의 AI 코딩 에이전트 비교 글과도 연결된다. 단순히 “어느 도구가 더 똑똑하다”가 아니라, 내 프로젝트에서 어떤 작업을 맡길 때 성공률과 비용이 좋은지를 봐야 한다.
실무 적용 체크리스트
- 반복되는 버그 수정 작업 10개를 샘플로 만든다.
- 각 에이전트에 같은 브랜치와 같은 지시문을 준다.
- 테스트 통과 여부, 수정 파일 수, 실행 시간, 토큰 비용을 기록한다.
- 성공률만 보지 말고 리뷰 가능한 코드인지 확인한다.
- 팀 규칙과 이전 의사결정을 에이전트가 참조할 수 있게 문서화한다.
FAQ
Agentic harness는 일반 벤치마크와 무엇이 다른가요?
일반 벤치마크가 모델의 답변 능력을 본다면, agentic harness는 에이전트가 실제 개발 작업을 수행하는 전체 과정을 평가한다.
개인 개발자도 이런 평가가 필요한가요?
필요한다. 특히 유료 모델을 여러 개 쓰는 경우, 작업 유형별 성공률과 비용을 기록하면 어떤 에이전트에 어떤 일을 맡길지 판단하기 쉬워집니다.